빅데이터 분석 특강 (10주차) 5월9일



- imports
- 로지스틱 모형 (1): 활성화함수로 sigmoid 선택
- 로지스틱 모형 (2): 활성화함수로 softmax 선택
- sigmoid, softmax
- 분류할 클래스가 3개 이상일 경우 신경망 모형의 설계
- Fashion_MNIST 다중분류
- 숙제
- 평가지표
- 더 좋은 모형을 만들고 싶은데..
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import tensorflow.experimental.numpy as tnp
tf.config.experimental.list_physical_devices()
import graphviz
def gv(s): return graphviz.Source('digraph G{ rankdir="LR"'+ s + ';}')
- 기본버전은 아래와 같다
$$y_i \approx \text{sigmoid}(b + w_1 x_{1,i} + \dots + w_{784}x_{784,i})= \frac{\exp(b + w_1 x_{1,i} + \dots + w_{784}x_{784,i})}{1+\exp(b + w_1 x_{1,i} + \dots + w_{784}x_{784,i})}$$
항상 0보다 클 것이고 분자가 분모보다 작아 1보다 작을 것이다.
- 벡터버전은 아래와 같다.
sigmoid는 broadcasting이 되어야 한다.
- 벡터버전에 익숙해지도록 하자. 벡터버전에 사용된 차원 및 연산을 정리하면 아래와 같다.
-
${\bf X}$: (n,784) matrix
-
${\boldsymbol y}$: (n,1) matrix
-
${\bf W}$: (784,1) matrix
-
$b$: (1,1) matrix
-
+,exp는 브로드캐스팅
다차원 확장이 편해진다.
0 또는 1로 정하는 이유, 0,1일 확률
- class 를 나타낼 때는 이름을 갖는 스트링을 0 또는 1로 치환한 거니까 1,2,3... 순서로 표현하는 건 적절하지 않다.
- $y_i=0 \text{ or } 1$ 대신에 $\boldsymbol{y}_i=[y_{i1},y_{i2}]= [1,0] \text { or } [0,1]$와 같이 코딩하면 어떠할까? (즉 원핫인코딩을 한다면?)
- n by 2 matrix 가 되겠군!
- 활성화 함수를 취하기 전의 버전은 아래와 같이 볼 수 있다.
$$[{\boldsymbol y}_1 ~ {\boldsymbol y}_2] \propto [ {\bf X}{\bf W}_1 ~ {\bf X}{\bf W}_2] + [b_1 ~ b_2]= {\bf X} [{\bf W}_1 {\bf W}_2] + [b_1 ~ b_2]= {\bf X}{\bf W} + {\boldsymbol b}$$
여기에서 매트릭스 및 연산의 차원을 정리하면 아래와 같다.
-
${\bf X}$: (n,784) matrix
-
${\boldsymbol y}_1,{\boldsymbol y}_2$: (n,1) matrix
-
${\boldsymbol y}:=[{\boldsymbol y}_1~ {\boldsymbol y}_2]$: (n,2) matrix
-
${\bf W}_1$, ${\bf W}_2$: (784,1) matrix
-
${\bf W}:=[{\bf W}_1~ {\bf W}_2]$: (784,2) matrix
-
$b_1,b_2$: (1,1) matrix
-
$\boldsymbol{b}:= [b_1 ~b_2] $: (1,2) matrix
-
+는 브로드캐스팅
- 즉 로지스틱 모형 (1)의 형태를 겹쳐놓은 형태로 해석할 수 있음. 따라서 ${\bf X} {\bf W}_1 + b_1$와 ${\bf X} {\bf W}_2 + b_2$의 row값이 클수록 ${\boldsymbol y}_1$와 ${\boldsymbol y}_2$의 row값이 1이어야 함
- ${\boldsymbol y}_1 \propto {\bf X} {\bf W}_1 + b_1$ $\to$ ${\bf X} {\bf W}_1 + b_1$의 row값이 클수록 $\boldsymbol{y}_1$의 row 값이 1이라면 모형계수를 잘 추정한것
- ${\boldsymbol y}_2 \propto {\bf X} {\bf W}_2 + b_2$ $\to$ ${\bf X} {\bf W}_2 + b_2$의 row값이 클수록 $\boldsymbol{y}_2$의 row 값을 1이라면 모형계수를 잘 추정한것
- (문제) ${\bf X}{\bf W}_1 +b_1$의 값이 500, ${\bf X}{\bf W}_2 +b_2$의 값이 200 인 row가 있다고 하자. 대응하는 $\boldsymbol{y}_1, \boldsymbol{y}_2$의 row값은 얼마로 적합되어야 하는가?
(1) $[0,0]$
(2) $[0,1]$
(3) $[1,0]$ <-- 이게 답이다!
(4) $[1,1]$
- 목표: 위와 같은 문제의 답을 유도해주는 활성화함수를 설계하자. 즉 합리적인 $\hat{\boldsymbol{y}}_1,\hat{\boldsymbol{y}}_2$를 구해주는 활성화 함수를 설계해보자. 이를 위해서는 아래의 사항들이 충족되어야 한다.
(1) $\hat{\boldsymbol{y}}_1$, $\hat{\boldsymbol{y}}_2$의 각 원소는 0보다 크고 1보다 작아야 한다. (확률을 의미해야 하니까)
(2) $\hat{\boldsymbol{y}}_1+\hat{\boldsymbol{y}}_2={\bf 1}$ 이어야 한다. (확률의 총합은 1이니까!)
(3) $\hat{\boldsymbol{y}}_1$와 $\hat{\boldsymbol{y}}_2$를 각각 따로해석하면 로지스틱처럼 되면 좋겠다.
- 아래와 같은 활성화 함수를 도입하면 어떨까?
- (1),(2)는 만족하는 듯 하다. (3)은 바로 이해되지는 않는다
(1) $\hat{\boldsymbol{y}}_1$, $\hat{\boldsymbol{y}}_2$의 각 원소는 0보다 크고 1보다 작아야 한다. --> OK!
(2) $\hat{\boldsymbol{y}}_1+\hat{\boldsymbol{y}}_2={\bf 1}$ 이어야 한다. --> OK!
(3) $\hat{\boldsymbol{y}}_1$와 $\hat{\boldsymbol{y}}_2$를 각각 따로해석하면 로지스틱처럼 되면 좋겠다. --> ???
- 그런데 조금 따져보면 (3)도 만족된다는 것을 알 수 있다. (sigmoid, softmax Section 참고)
- 위와 같은 함수를 softmax라고 하자. 즉 아래와 같이 정의하자.
- 아래의 수식을 관찰하자.
$$\frac{\exp(\beta_0+\beta_1 x_i)}{1+\exp(\beta_0+\beta_1x_i)}=\frac{\exp(\beta_0+\beta_1 x_i)}{e^0+\exp(\beta_0+\beta_1x_i)}$$
- 1을 $e^0$로 해석하면 모형2의 해석을 아래와 같이 모형1의 해석으로 적용할수 있다.
- 모형2: ${\bf X}\hat{\bf W}_1 +\hat{b}_1$ 와 ${\bf X}\hat{\bf W}_2 +\hat{b}_2$ 의 크기를 비교하고 확률 결정
- 모형1: ${\bf X}\hat{\bf W} +\hat{b}$ 와 $0$의 크기를 비교하고 확률 결정 = ${\bf X}\hat{\bf W} +\hat{b}$의 row값이 양수이면 1로 예측하고 음수이면 0으로 예측
- 이항분포를 차원이 2인 다항분포로 해석가능한 것처럼 sigmoid는 차원이 2인 softmax로 해석가능하다. 즉 다항분포가 이항분포의 확장형으로 해석가능한 것처럼 softmax도 sigmoid의 확장형으로 해석가능하다.
- 클래스 2개면 sigmoid 클래스 3개 이상이면 softmax
- 언뜻 생각하면 클래스가 2인 경우에도 sigmoid 대신 softmax로 활성화함수를 이용해도 될 듯 하다. 즉 $y=0 \text{ or } 1$와 같이 정리하지 않고 $y=[0,1] \text{ or } [1,0]$ 와 같이 정리해도 무방할 듯 하다.
- 하지만 sigmoid가 좀 더 좋은 선택이다. 즉 $y= 0 \text{ or } 1$로 데이터를 정리하는 것이 더 좋은 선택이다. 왜냐하면 sigmoid는 softmax와 비교하여 파라메터의 수가 적지만 표현력은 동등하기 때문이다.
- 표현력이 동등한 이유? 아래 수식을 관찰하자.
$$\big(\frac{e^{300}}{e^{300}+e^{500}},\frac{e^{500}}{e^{300}+e^{500}}\big) =\big( \frac{e^{0}}{e^{0}+e^{200}}, \frac{e^{200}}{e^{0}+e^{200}}\big)$$
- $\big(\frac{e^{300}}{e^{300}+e^{500}},\frac{e^{500}}{e^{300}+e^{500}}\big)$를 표현하기 위해서 300, 500 이라는 2개의 숫자가 필요한것이 아니고 따지고보면 200이라는 하나의 숫자만 필요하다.
- $(\hat{\boldsymbol{y}}_1,\hat{\boldsymbol{y}}_2)$의 표현에서도 ${\bf X}\hat{\bf W}_1 +\hat{b}_1$ 와 ${\bf X}\hat{\bf W}_2 +\hat{b}_2$ 라는 숫자 각각이 필요한 것이 아니고 $({\bf X}\hat{\bf W}_1 +\hat{b}_1)-({\bf X}\hat{\bf W}_2 +\hat{b}_2)$의 값만 알면 된다.
- 여기서는 (500-300=200)만 알면 되겠지!
- 클래스의 수가 2개일 경우는 softmax가 sigmoid에 비하여 장점이 없다. 하지만 softmax는 클래스의 수가 3개 이상일 경우로 쉽게 확장할 수 있다는 점에서 매력적인 활성화 함수이다.
클래스가 10개일때
- y의 모양: [0 1 0 0 0 0 0 0 0 0]
- 활성화함수의 선택: softmax
- 손실함수의 선택: cross entropy
- 데이터정리
- 시도1: 간단한 신경망
gv('''
splines=line
subgraph cluster_1{
style=filled;
color=lightgrey;
"x1"
"x2"
".."
"x784"
label = "Layer 0"
}
subgraph cluster_2{
style=filled;
color=lightgrey;
"x1" -> "node1"
"x2" -> "node1"
".." -> "node1"
"x784" -> "node1"
"x1" -> "node2"
"x2" -> "node2"
".." -> "node2"
"x784" -> "node2"
"x1" -> "..."
"x2" -> "..."
".." -> "..."
"x784" -> "..."
"x1" -> "node30"
"x2" -> "node30"
".." -> "node30"
"x784" -> "node30"
label = "Layer 1: relu"
}
subgraph cluster_3{
style=filled;
color=lightgrey;
"node1" -> "y10"
"node2" -> "y10"
"..." -> "y10"
"node30" -> "y10"
"node1" -> "y1"
"node2" -> "y1"
"..." -> "y1"
"node30" -> "y1"
"node1" -> "."
"node2" -> "."
"..." -> "."
"node30" -> "."
label = "Layer 2: softmax"
}
''')
y는 10차원이 되겠지, [] 안에 있는 수만큼
Fashion_MNIST 다중분류
- 데이터정리
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
tf.keras.utils.to_categorical(y_train)
X=x_train.reshape(-1,784) # 60000 by 784
y=tf.keras.utils.to_categorical(y_train) # 위처럼 10을 정렬하여 1 또는 0으로
XX=x_test.reshape(-1,784)
yy=tf.keras.utils.to_categorical(y_test)
tf.random.set_seed(43052)
net1 = tf.keras.Sequential()
net1.add(tf.keras.layers.Dense(30,activation='relu')) # 따로 써도 되고 같이 써도 되는 활성화함수
net1.add(tf.keras.layers.Dense(10,activation='softmax')) # y가 10이니까
net1.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics=['accuracy'])
net1.fit(X,y,epochs=20,batch_size=1200)
net1.evaluate(XX,yy)
net1.summary()
- 시도2: 더 깊은 신경망
gv('''
splines=line
subgraph cluster_1{
style=filled;
color=lightgrey;
"x1"
"x2"
".."
"x784"
label = "Layer 0"
}
subgraph cluster_2{
style=filled;
color=lightgrey;
"x1" -> "node1"
"x2" -> "node1"
".." -> "node1"
"x784" -> "node1"
"x1" -> "node2"
"x2" -> "node2"
".." -> "node2"
"x784" -> "node2"
"x1" -> "..."
"x2" -> "..."
".." -> "..."
"x784" -> "..."
"x1" -> "node500"
"x2" -> "node500"
".." -> "node500"
"x784" -> "node500"
label = "Layer 1: relu"
}
subgraph cluster_3{
style=filled;
color=lightgrey;
"node1" -> "node1(2)"
"node2" -> "node1(2)"
"..." -> "node1(2)"
"node500" -> "node1(2)"
"node1" -> "node2(2)"
"node2" -> "node2(2)"
"..." -> "node2(2)"
"node500" -> "node2(2)"
"node1" -> "...."
"node2" -> "...."
"..." -> "...."
"node500" -> "...."
"node1" -> "node500(2)"
"node2" -> "node500(2)"
"..." -> "node500(2)"
"node500" -> "node500(2)"
label = "Layer 2: relu"
}
subgraph cluster_4{
style=filled;
color=lightgrey;
"node1(2)" -> "y10"
"node2(2)" -> "y10"
"...." -> "y10"
"node500(2)" -> "y10"
"node1(2)" -> "y1"
"node2(2)" -> "y1"
"...." -> "y1"
"node500(2)" -> "y1"
"node1(2)" -> "."
"node2(2)" -> "."
"...." -> "."
"node500(2)" -> "."
label = "Layer 3: softmax"
}
''')
tf.random.set_seed(43052)
net2 = tf.keras.Sequential()
net2.add(tf.keras.layers.Dense(500,activation='relu'))
net2.add(tf.keras.layers.Dense(500,activation='relu'))
net2.add(tf.keras.layers.Dense(10,activation='softmax'))
net2.compile(optimizer='adam',loss=tf.losses.categorical_crossentropy,metrics=['accuracy'])
net2.fit(X,y,epochs=50,batch_size=1200)
net2.evaluate(XX,yy)
net2.summary()
훨씬 파라미터를 많이 썼네!
- 시도1,2에서 사용된 모형에서 각각 추정해야할 파라메터의 수를 구하고 비교하라.
hint: net.summary() 이용
시도 1
net1.summary()
net1.evaluate(XX,yy)
시도 2
net2.summary()
net2.evaluate(XX,yy)
- 시도 2가 사용한 파라메터의 수가 더 많다.
- 정확도는 시도 2가 더 높았다.
- 의문: 왜 다양한 평가지표가 필요한가? (accuray면 끝나는거 아닌가? 더 이상 뭐가 필요해?)
- 여러가지 평가지표들: https://en.wikipedia.org/wiki/Positive_and_negative_predictive_values
- 이걸 다 암기하는건 불가능함.
- 몇 개만 뽑아서 암기하고 왜 쓰는지만 생각해보고 넘어가자!
- 표1
| 퇴사(예측) | 안나감(예측) | |
|---|---|---|
| 퇴사(실제) | TP | FN |
| 안나감(실제) | FP | TN |
True/Positive/False/Negative
- 표2 (책에없음)
| 퇴사(예측) | 안나감(예측) | |
|---|---|---|
| 퇴사(실제) | $(y,\hat{y})= $ (O,O) | $(y,\hat{y})= $(O,X) |
| 안나감(실제) | $(y,\hat{y})= $(X,O) | $(y,\hat{y})= $(X,X) |
- 표3 (책에없음)
| 퇴사(예측) | 안나감(예측) | |
|---|---|---|
| 퇴사(실제) | TP, $\# O/O$ | FN, $\#O/X$ |
| 안나감(실제) | FP, $\#X/O$ | TN, $\#X/X$ |
- 암기법, (1) 두번째 글자를 그대로 쓴다 (2) 첫글자가 T이면 분류를 제대로한것, 첫글자가 F이면 분류를 잘못한것
- 표4 (위키등에 있음)
| 퇴사(예측) | 안나감(예측) | ||
|---|---|---|---|
| 퇴사(실제) | TP, $\# O/O$ | FN, $\# O/X$ | Sensitivity(민감도)=Recall(재현율)=$\frac{TP}{TP+FN}$=$\frac{\#O/O}{\# O/O+ \#O/X}$ |
| 안나감(실제) | FP, $\# X/O$ | TN, $\# X/X$ | |
| Precision(프리시즌)=$\frac{TP}{TP+FP}$=$\frac{\# O/O}{\# O/O+\# X/O}$ | Accuracy(애큐러시)=$\frac{TP+TN}{total}$=$\frac{\#O/O+\# X/X}{total}$ |
- 최규빈은 입사하여 "퇴사자 예측시스템"의 개발에 들어갔다.
- 자료의 특성상 대부분의 사람이 퇴사하지 않고 회사에 잘 다닌다. 즉 1000명이 있으면 10명정도 퇴사한다.
- 정의: Accuracy(애큐러시)=$\frac{TP+TN}{total}$=$\frac{\#O/O+ \#X/X}{total}$
- 한국말로는 정확도, 정분류율이라고 한다.
- 한국말이 헷갈리므로 그냥 영어를 외우는게 좋다. (어차피 Keras에서 옵션도 영어로 넣음)
- (상확극 시점1) 왜 애큐러시는 불충분한가?
- 회사: 퇴사자예측프로그램 개발해
- 최규빈: 귀찮은데 다 안 나간다고 하자! -> 99퍼의 accuracy
모델에 사용한 파라메터 = 0. 그런데 애큐러시 = 99! 이거 엄청 좋은 모형이다?
예측이 아니라.. 예상으로 그칠 듯, 결과와 비교하면? 맞지도 않을걸
- 정의: Sensitivity(민감도)=Recall(재현율)=$\frac{TP}{TP+FN}$=$\frac{\# O/O}{\# O/O+\# O/X}$
- 분모: 실제 O인 관측치 수
- 분자: 실제 O를 O라고 예측한 관측치 수
- 뜻: 실제 O를 O라고 예측한 비율
- (상황극 시점2) recall을 봐야하는 이유
- 인사팀: 실제 퇴사자를 퇴사자로 예측해야 의미가 있음! 우리는 퇴사할것 같은 10명을 찍어달란 의미였어요! (그래야 면담을 하든 할거아냐!)
- 최규빈: 가볍고(=파라메터 적고) 잘 맞추는 모형 만들어 달라면서요?
- 인사팀: (고민중..) 사실 생각해보니까 이 경우는 애큐러시는 의미가 없네. 실제 나간 사람 중 최규빈이 나간다고 한 사람이 몇인지 카운트 하는게 더 의미가 있겠다. 우리는 앞으로 리컬(혹은 민감도)를 보겠다!
예시1:실제로 퇴사한 10명중 최규빈이 나간다고 찍은 사람이 5명이면 리컬이 50% > 예시2:최규빈이 아무도 나가지 않는다고 예측해버린다? 실제 10명중에서 최규빈이 나간다고 적중시킨사람은 0명이므로 이 경우 리컬은 0%
- 결론: 우리가 필요한건 recall이니까 앞으로 recall을 가져와! accuracy는 큰 의미없어. (그래도 명색이 모델인데 accuracy가 90은 되면 좋겠다)
- 정의: Precision(프리시즌)=$\frac{TP}{TP+FP}$=$\frac{\# O/O}{\# O/O+\# X/O}$
- 분모: O라고 예측한 관측치
- 분자: O라고 예측한 관측치중 진짜 O인 관측치
- 뜻: O라고 예측한 관측치중 진짜 O인 비율
- (상황극 시점3) recall 만으로 불충분한 이유
- 최규빈: 에휴.. 귀찮은데 그냥 좀만 수틀리면 다 나갈것 같다고 해야겠다. -> 한 100명 나간다고 했음 -> 실제로 최규빈이 찍은 100명중에 10명이 다 나감!
- 0.1만 넘어도 나간다고 해버리면?
이 경우 애큐러시는 91%, 리컬은 100% (퇴사자 10명을 일단은 다 맞췄으므로).
-
인사팀: (화가 많이 남) 멀쩡한 사람까지 다 퇴사할 것 같다고 하면 어떡해요? 최규빈 연구원이 나간다고 한 100명중에 실제로 10명만 나갔어요.
-
인사팀: 마치 총으로 과녁중앙에 맞춰 달라고 했더니 기관총을 가져와서 한번 긁은것이랑 뭐가 달라요? 맞추는게 문제가 아니고 precision이 너무 낮아요.
- 최규빈: accuracy 90% 이상, recall은 높을수록 좋다는게 주문 아니었나요?
- 인사팀: (고민중..) 앞으로는 recall과 함께 precision도 같이 제출하세요. precision은 당신이 나간다고 한 사람중에 실제 나간사람의 비율을 의미해요. 이 경우는 $\frac{10}{100}$이니까 precision이 10%입니다. (속마음: recall 올리겠다고 무작정 너무 많이 예측하지 말란 말이야!)
- 정의: recall과 precision의 조화평균
- (상황극 시점4) recall, precision을 모두 고려
-
최규빈: recall/precision을 같이 내는건 좋은데요, 둘은 trade off의 관계에 있습니다. 물론 둘다 올리는 모형이 있다면 좋지만 그게 쉽지는 않아요. 보통은 precision을 올리려면 recall이 희생되는 면이 있고요, recall을 올리려고 하면 precision이 다소 떨어집니다.
-
최규빈: 평가기준이 애매하다는 의미입니다. 모형1,2가 있는데 모형1은 모형2보다 precision이 약간 좋고 대신 recall이 떨어진다면 모형1이 좋은것입니까? 아니면 모형2가 좋은것입니까?
- 인사팀: 그렇다면 둘을 평균내서 F1score를 계산해서 제출해주세요.
- 정의:
(1) Specificity(특이도)=$\frac{TN}{FP+TN}$=$\frac{\# X/X}{\# X/O+\# X/X}$
(2) False Positive Rate (FPR) = 1-Specificity(특이도) = $\frac{FP}{FP+TN}$=$\frac{\# X/O}{\# X/O+\# X/X}$
- 의미: FPR = 오해해서 미안해, recall(=TPR)을 올리려고 보니 어쩔 수 없었어 ㅠㅠ
- specificity는 안나간 사람을 안나갔다고 찾아낸 비율인데 별로 안중요하다.
- FPR은 recall을 올리기 위해서 "실제로는 회사 잘 다니고 있는 사람 중 최규빈이 나갈것 같다고 찍은 사람들" 의 비율이다.
즉 생사람잡은 비율.. 오해해서 미안한 사람의 비율.. (recall 올리다가 희생된 사람)
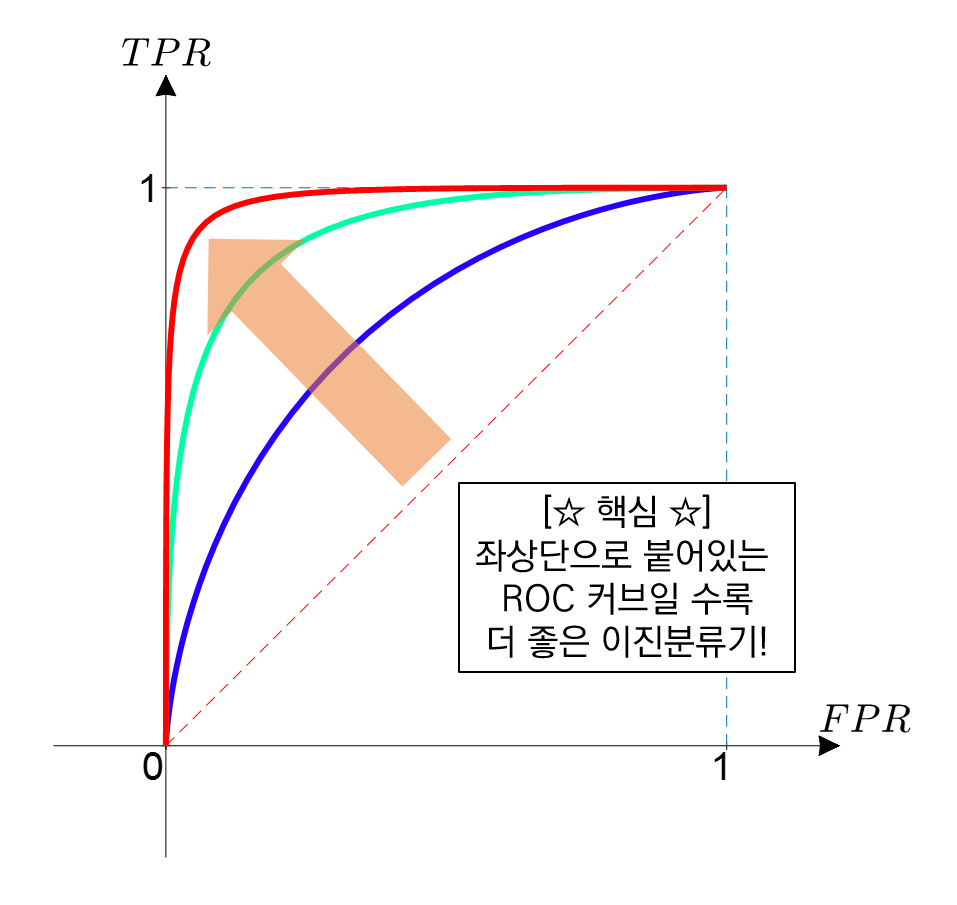
- 정의: $x$축=FPR, $y$축=TPR 을 그린 커브
- 의미:
- 결국 "오해해서 미안해 vs recall"을 그린 곡선이 ROC커브이다.
- 생각해보면 오해하는 사람이 많을수록 당연히 recall은 올라간다. 따라서 우상향하는 곡선이다.
- 오해한 사람이 매우 적은데 recall이 우수하면 매우 좋은 모형이다. 그래서 초반부터 ROC값이 급격하게 올라가면 좋은 모형이다.
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
tnp.experimental_enable_numpy_behavior()
import matplotlib.pyplot as plt
- fashion mnist data 다시 불러오자
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train.shape
- 이미지는 원래 가로픽셀 세로픽셀 3 이어야 한다. (색을 표현하는 basis는 빨,녹,파)
- 따라서 이미지의 차원이 단지 (28,28)이라는 것은 흑백이미지라는 뜻이다.
x_train[0].shape # 첫번째 인덱싱을 뽑아
plt.imshow(x_train[0])

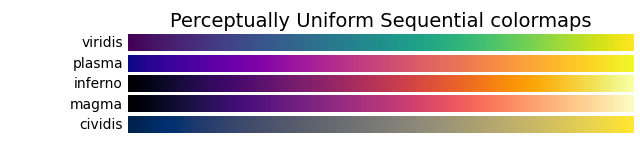
- 아닌데요?! 칼라인데요?! -> 흑백이다. 그냥 밝을수록 노란색, 어두울수록 남색으로 표현한것 뿐임 (colormap이 viridis일 뿐임)
- 밑에처럼 빛의 색 표현 방법 중 하나일 뿐
- 일반적으로 분석할 이미지는 칼라를 의미하는 채널도 포함할테니 아래와 같이 자료형을 정리하는게 일반적으로 이미지 자료를 분석하는 정석적인 처리방법이다.
- 이미지 데이터를 분류하기 좋은 형태로 자료를 재정리 하자
- 0~ 255 사이로 표현되는 수들로 표현하여 float을 맞춰주자
X = tf.constant(x_train.reshape(-1,28,28,1),dtype=tf.float64)
y = tf.keras.utils.to_categorical(y_train)
XX = tf.constant(x_test.reshape(-1,28,28,1),dtype=tf.float64)
yy = tf.keras.utils.to_categorical(y_test)
- 일반적인 이미지 분석 모형을 적용하기 용이한 데이터 형태로 정히했다 $\to$ 그런데 모형에 넣고 돌리려면 다시 차원을 펼쳐야 하지 않을까>
- 안 펼치고 하고 싶다.
y
X.shape, XX.shape
- keras에서 이미지자료는 (관측치수,픽셀,픽셀,채널)과 같은 형식을 가진다.
- 예를들어 256*256 size인 칼라이미지(채널수=3)가 10개 있다면 X.shape은 (10,256,256,3)이다.
- 이러한 아키텍처를 돌리기 위해서는 X의 shape을 미리 바꿔야 했었다. 혹시 바꾸지 않는 방법도 있을까?
- tf.keras.layers.Flatten()
flttn = tf.keras.layers.Flatten()
flttn
- type: flatten <- 머 어쩌란거야..
dir(flttn)
set(dir(flttn)) & {'__call__'}
- call이 있음 -> 써보자
- 함수처럼 쓸 수 있다는 뜻이랬지~
- call 이 있는게 특이한 경우래....
- set으로 집합 만들어서 교집합 있나 봐봐, 보기 편하네..!
set(dir(flttn)) & {'__iterl__'}
- direc에 iter가 있다는 뜻은 for 문을 쓸 수 있다는 뜻!!!
X.shape
flttn(X) # 오..?
펴진다? 즉 X.reshape(-1,784)와 같은 기능!
flttn(X).shape, X.reshape(60000,-1).shape, X.reshape(-1,784).shape
같은 결과!
- 근데 이거 레이어다? 즉 네트워크에 add 할 수 있다는 의미!
- reshape은 layer에 넣지 못한다.
- 그렇다면 아래와 같이 예제를 풀어도 괜찮겠다.
tf.random.set_seed(43052)
net1 = tf.keras.Sequential()
net1.add(tf.keras.layers.Flatten())
net1.add(tf.keras.layers.Dense(30,activation='relu'))
net1.add(tf.keras.layers.Dense(10,activation='softmax'))
net1.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=['accuracy'])
net1.fit(X,y,epochs=5)
epoch 생략하면 한 번 돈다
X의 shape은 유지하되 network 돌리기~
- 관찰
net1.layers
print(X.shape)
print(net1.layers[0](X).shape)
print(net1.layers[1](net1.layers[0](X)).shape)
print(net1.layers[2](net1.layers[1](net1.layers[0](X))).shape)
net1.layers[0](X) # 레이어를 통과하는 순간 전처리!
net1.layers[1](net1.layers[0](X)) # 출력이 30이니까~ + 렐루를 거쳐서 0또는 양수인 모습!
net1.layers[2](net1.layers[1](net1.layers[0](X))) # 최종출력 10차원, 각각은 확률을 의미하게 된다.
- (참고) metrics=['accuracy'] 대신에 이렇게 해도된다~
tf.random.set_seed(43052)
net1 = tf.keras.Sequential()
net1.add(tf.keras.layers.Flatten())
net1.add(tf.keras.layers.Dense(30,activation='relu'))
net1.add(tf.keras.layers.Dense(10,activation='softmax'))
net1.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=[tf.metrics.CategoricalAccuracy()])
net1.fit(X,y,epochs=5)
id(tf.metrics.CategoricalAccuracy), id(tf.keras.metrics.CategoricalAccuracy)
- 주소가 똑같네요, 이게 무슨말인지 알죠?
- 같은 역할한다는 뜻~
- 나중에
accuracy2 개 쓰게 되면 겹칠 수 있다.
- 주의사항: tf.metrics.Accuracy() 말고 tf.metrics.CategoricalAccuracy() 를 써야함
tf.random.set_seed(43052)
net1 = tf.keras.Sequential()
net1.add(tf.keras.layers.Flatten())
net1.add(tf.keras.layers.Dense(30,activation='relu'))
net1.add(tf.keras.layers.Dense(10,activation='softmax'))
net1.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=['accuracy','recall'])
net1.fit(X,y)
안 된다?
tf.random.set_seed(43052)
net1 = tf.keras.Sequential()
net1.add(tf.keras.layers.Flatten())
net1.add(tf.keras.layers.Dense(30,activation='relu'))
net1.add(tf.keras.layers.Dense(10,activation='softmax'))
net1.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=['accuracy','Recall'])
net1.fit(X,y)
된다?
tf.random.set_seed(43052)
net1 = tf.keras.Sequential()
net1.add(tf.keras.layers.Flatten())
net1.add(tf.keras.layers.Dense(30,activation='relu'))
net1.add(tf.keras.layers.Dense(10,activation='softmax'))
net1.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=['Accuracy','Recall'])
net1.fit(X,y)
된다?
- (참고2) 메트릭을 추가할수도 있다
tf.random.set_seed(43052)
net1 = tf.keras.Sequential()
net1.add(tf.keras.layers.Flatten())
net1.add(tf.keras.layers.Dense(30,activation='relu'))
net1.add(tf.keras.layers.Dense(10,activation='softmax'))
net1.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=[tf.metrics.CategoricalAccuracy(),tf.metrics.Recall()])
net1.fit(X,y,epochs=5)
- 리콜을 추가하면 test set의 성능평가에도 리콜을 볼 수 있다.
net1.evaluate(XX,yy)
loss, accuracy, recall 모두 나오지~
net1.summary()
- 다른모형으로도 적합시켜보자.
tf.random.set_seed(43052)
net2 = tf.keras.Sequential()
net2.add(tf.keras.layers.Flatten())
net2.add(tf.keras.layers.Dense(500,activation='relu'))
net2.add(tf.keras.layers.Dense(500,activation='relu'))
net2.add(tf.keras.layers.Dense(10,activation='softmax'))
net2.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=['accuracy'])
net2.fit(X,y,epochs=5)
net2.fit(XX,yy)
net2.summary()
- 좀 더 돌려보자.
tf.random.set_seed(43052)
net2 = tf.keras.Sequential()
net2.add(tf.keras.layers.Flatten())
net2.add(tf.keras.layers.Dense(500,activation='relu'))
net2.add(tf.keras.layers.Dense(500,activation='relu'))
net2.add(tf.keras.layers.Dense(10,activation='softmax'))
net2.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=['accuracy'])
net2.fit(X,y,epochs=10)
net2.fit(XX,yy)
- 이 이상은 비효율적인듯..
- 무지성: 아 몰라 딥러닝이 해주겠지
tf.random.set_seed(43052)
net3 = tf.keras.Sequential()
net3.add(tf.keras.layers.Flatten())
net3.add(tf.keras.layers.Dense(500,activation='relu'))
net3.add(tf.keras.layers.Dense(500,activation='relu'))
net3.add(tf.keras.layers.Dense(500,activation='relu'))
net3.add(tf.keras.layers.Dense(500,activation='relu'))
net3.add(tf.keras.layers.Dense(500,activation='relu'))
net3.add(tf.keras.layers.Dense(10,activation='softmax'))
net3.compile(loss=tf.losses.categorical_crossentropy, optimizer='adam',metrics=['accuracy'])
net3.fit(X,y,epochs=10)
net3.evaluate(XX,yy)
net2.summary()
net3.summary()
위 파라메터의 수 의 일부분만 사용하고 accuracy를 늘릴 것,
- 저렇게 짜야하는 이론 이런 거 없어..
- 파라메터 증가대비 그닥..
- 왠지 DNN계열로는 한계가 있어보인다.