Simulation Tables
import
data_fivenodes = pd.read_csv('./simulation_results/Real_simulation_reshape/GConvLSTM_fivedones_Simulation.csv')
data_chickenpox = pd.read_csv('./simulation_results/Real_simulation_reshape/GConvLSTM_chikenpox_Simulation.csv')
data_pedal = pd.read_csv('./simulation_results/Real_simulation_reshape/GConvLSTM_pedalme_Simulation.csv')
data_pedal2 = pd.read_csv('./simulation_results/Real_simulation_reshape/GConvLSTM_pedalme_Simulation_itstgcnsnd.csv')
data__wiki = pd.read_csv('./simulation_results/Real_simulation_reshape/GConvLSTM_wikimath.csv')
data_wiki_GSO = pd.read_csv('./simulation_results/Real_simulation_reshape/GConvLSTM_wikimath_GSO_st.csv')
data_windmillsmall = pd.read_csv('./simulation_results/Real_simulation_reshape/GConvLSTM_windmillsmall.csv')
data_monte = pd.read_csv('./simulation_results/Real_simulation_reshape/GConvLSTM_monte.csv')
data = pd.concat([data_fivenodes,data_chickenpox,data_pedal,data__wiki,data_windmillsmall,data_monte]);data
| 0 |
fivenodes |
STGCN |
0.7 |
rand |
2 |
12 |
linear |
50 |
1.400281 |
68.264710 |
| 1 |
fivenodes |
STGCN |
0.7 |
rand |
2 |
12 |
nearest |
50 |
1.388435 |
61.920614 |
| 2 |
fivenodes |
IT-STGCN |
0.7 |
rand |
2 |
12 |
linear |
50 |
1.397660 |
52.695602 |
| 3 |
fivenodes |
IT-STGCN |
0.7 |
rand |
2 |
12 |
nearest |
50 |
1.308839 |
76.363896 |
| 4 |
fivenodes |
STGCN |
0.7 |
rand |
2 |
12 |
linear |
50 |
1.416825 |
69.100783 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 355 |
monte |
IT-STGCN |
0.7 |
rand |
4 |
12 |
nearest |
50 |
1.018768 |
747.551331 |
| 356 |
monte |
STGCN |
0.7 |
rand |
4 |
12 |
nearest |
50 |
1.101372 |
667.532505 |
| 357 |
monte |
IT-STGCN |
0.7 |
rand |
4 |
12 |
nearest |
50 |
0.993775 |
750.078657 |
| 358 |
monte |
STGCN |
0.7 |
rand |
4 |
12 |
nearest |
50 |
1.041690 |
675.276535 |
| 359 |
monte |
IT-STGCN |
0.7 |
rand |
4 |
12 |
nearest |
50 |
0.990655 |
746.587422 |
2882 rows × 10 columns
data.to_csv('./simulation_results/Real_simulation_reshape/Final_Simulation_GConvLSTM.csv',index=False)
pedal_wiki_GSO = pd.concat([data_pedal2,data_wiki_GSO])
pedal_wiki_GSO.to_csv('./simulation_results/Real_simulation_reshape/Final_Simulation_GConvLSTM_pedal_wiki_GSO.csv',index=False)
Fivenodes
Baseline
pd.merge(data.query("dataset=='fivenodes' and mtype!='rand' and mtype!='block'").groupby(['nof_filters','method','lags'])['mse'].mean().reset_index(),
data.query("dataset=='fivenodes' and mtype!='rand' and mtype!='block'").groupby(['nof_filters','method','lags'])['mse'].std().reset_index(),
on=['method','nof_filters','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
12 |
IT-STGCN |
2 |
1.126 |
0.034 |
| 1 |
12 |
STGCN |
2 |
1.137 |
0.047 |
Random
pd.merge(data.query("dataset=='fivenodes' and mtype=='rand'").groupby(['inter_method','mrate','nof_filters','method','lags'])['mse'].mean().reset_index(),
data.query("dataset=='fivenodes' and mtype=='rand'").groupby(['inter_method','mrate','nof_filters','method','lags'])['mse'].std().reset_index(),
on=['method','inter_method','nof_filters','mrate','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3).query("nof_filters==12")
| 0 |
linear |
0.7 |
12 |
IT-STGCN |
2 |
1.287 |
0.075 |
| 1 |
linear |
0.7 |
12 |
STGCN |
2 |
1.472 |
0.125 |
| 2 |
linear |
0.8 |
12 |
IT-STGCN |
2 |
1.298 |
0.060 |
| 3 |
linear |
0.8 |
12 |
STGCN |
2 |
1.442 |
0.111 |
| 4 |
nearest |
0.7 |
12 |
IT-STGCN |
2 |
1.261 |
0.077 |
| 5 |
nearest |
0.7 |
12 |
STGCN |
2 |
1.394 |
0.085 |
| 6 |
nearest |
0.8 |
12 |
IT-STGCN |
2 |
1.312 |
0.065 |
| 7 |
nearest |
0.8 |
12 |
STGCN |
2 |
1.436 |
0.098 |
Block
pd.merge(data.query("dataset=='fivenodes' and mtype=='block'").groupby(['inter_method','mrate','nof_filters','method'])['mse'].mean().reset_index(),
data.query("dataset=='fivenodes' and mtype=='block'").groupby(['inter_method','mrate','nof_filters','method'])['mse'].std().reset_index(),
on=['method','inter_method','nof_filters','mrate']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
linear |
0.125 |
12 |
IT-STGCN |
1.140 |
0.038 |
| 1 |
linear |
0.125 |
12 |
STGCN |
1.172 |
0.055 |
| 2 |
nearest |
0.125 |
12 |
IT-STGCN |
1.121 |
0.027 |
| 3 |
nearest |
0.125 |
12 |
STGCN |
1.140 |
0.058 |
ChickenpoxDatasetLoader(lags=4)
Baseline
pd.merge(data.query("dataset=='chickenpox' and mtype!='rand' and mtype!='block'").groupby(['nof_filters','method'])['mse'].mean().reset_index(),
data.query("dataset=='chickenpox' and mtype!='rand' and mtype!='block'").groupby(['nof_filters','method'])['mse'].std().reset_index(),
on=['method','nof_filters']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3).query("nof_filters==16")
Random
pd.merge(data.query("dataset=='chickenpox' and mtype=='rand'").groupby(['inter_method','mrate','nof_filters','method','lags'])['mse'].std().reset_index(),
data.query("dataset=='chickenpox' and mtype=='rand'").groupby(['inter_method','mrate','nof_filters','method','lags'])['mse'].std().reset_index(),
on=['method','inter_method','nof_filters','mrate','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
linear |
0.3 |
32 |
IT-STGCN |
4 |
0.035 |
0.035 |
| 1 |
linear |
0.3 |
32 |
STGCN |
4 |
0.057 |
0.057 |
| 2 |
linear |
0.8 |
32 |
IT-STGCN |
4 |
0.080 |
0.080 |
| 3 |
linear |
0.8 |
32 |
STGCN |
4 |
0.111 |
0.111 |
Block
pd.merge(data.query("dataset=='chickenpox' and mtype=='block'").groupby(['inter_method','mrate','nof_filters','method'])['mse'].mean().reset_index(),
data.query("dataset=='chickenpox' and mtype=='block'").groupby(['inter_method','mrate','nof_filters','method'])['mse'].std().reset_index(),
on=['method','inter_method','mrate','nof_filters']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
linear |
0.288 |
32 |
IT-STGCN |
0.911 |
0.069 |
| 1 |
linear |
0.288 |
32 |
STGCN |
0.900 |
0.049 |
| 2 |
nearest |
0.288 |
32 |
IT-STGCN |
0.885 |
0.040 |
| 3 |
nearest |
0.288 |
32 |
STGCN |
0.896 |
0.054 |
PedalMeDatasetLoader (lags=4)
Baseline
pd.merge(data.query("dataset=='pedalme' and mtype!='rand' and mtype!='block'").groupby(['lags','nof_filters','method'])['mse'].mean().reset_index(),
data.query("dataset=='pedalme' and mtype!='rand' and mtype!='block'").groupby(['lags','nof_filters','method'])['mse'].std().reset_index(),
on=['method','lags','nof_filters']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3).query("lags==4")
| 0 |
4 |
2 |
IT-STGCN |
1.213 |
0.050 |
| 1 |
4 |
2 |
STGCN |
1.215 |
0.059 |
Random
pd.merge(data.query("dataset=='pedalme' and mtype=='rand'").groupby(['mrate','lags','inter_method','method'])['mse'].mean().reset_index(),
data.query("dataset=='pedalme' and mtype=='rand'").groupby(['mrate','lags','inter_method','method'])['mse'].std().reset_index(),
on=['method','mrate','lags','inter_method']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
0.3 |
4 |
linear |
IT-STGCN |
1.227 |
0.056 |
| 1 |
0.3 |
4 |
linear |
STGCN |
1.244 |
0.041 |
| 2 |
0.3 |
4 |
nearest |
IT-STGCN |
1.224 |
0.035 |
| 3 |
0.3 |
4 |
nearest |
STGCN |
1.266 |
0.068 |
| 4 |
0.6 |
4 |
linear |
IT-STGCN |
1.255 |
0.049 |
| 5 |
0.6 |
4 |
linear |
STGCN |
1.332 |
0.089 |
| 6 |
0.6 |
4 |
nearest |
IT-STGCN |
1.248 |
0.045 |
| 7 |
0.6 |
4 |
nearest |
STGCN |
1.274 |
0.078 |
Block
pd.merge(data.query("dataset=='pedalme' and mtype=='block'").groupby(['mrate','lags','inter_method','method'])['mse'].mean().reset_index(),
data.query("dataset=='pedalme' and mtype=='block'").groupby(['mrate','lags','inter_method','method'])['mse'].std().reset_index(),
on=['method','mrate','lags','inter_method']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3).query("lags==4")
| 0 |
0.286 |
4 |
linear |
IT-STGCN |
1.241 |
0.069 |
| 1 |
0.286 |
4 |
linear |
STGCN |
1.223 |
0.042 |
| 2 |
0.286 |
4 |
nearest |
IT-STGCN |
1.222 |
0.039 |
| 3 |
0.286 |
4 |
nearest |
STGCN |
1.237 |
0.046 |
W_st
pd.merge(data_pedal2.query("mtype=='rand'").groupby(['mrate','lags','inter_method','method'])['mse'].mean().reset_index(),
data_pedal2.query("mtype=='rand'").groupby(['mrate','lags','inter_method','method'])['mse'].std().reset_index(),
on=['method','mrate','lags','inter_method']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3).query("lags==4")
| 0 |
0.3 |
4 |
linear |
IT-STGCN |
1.340 |
0.166 |
| 1 |
0.3 |
4 |
linear |
STGCN |
1.392 |
0.109 |
| 2 |
0.3 |
4 |
nearest |
IT-STGCN |
1.368 |
0.158 |
| 3 |
0.3 |
4 |
nearest |
STGCN |
1.338 |
0.118 |
| 4 |
0.6 |
4 |
linear |
IT-STGCN |
1.312 |
0.162 |
| 5 |
0.6 |
4 |
linear |
STGCN |
1.498 |
0.083 |
| 6 |
0.6 |
4 |
nearest |
IT-STGCN |
1.313 |
0.205 |
| 7 |
0.6 |
4 |
nearest |
STGCN |
1.503 |
0.101 |
pd.merge(data_pedal2.query("mtype=='block'").groupby(['mrate','lags','inter_method','method'])['mse'].mean().reset_index(),
data_pedal2.query("mtype=='block'").groupby(['mrate','lags','inter_method','method'])['mse'].std().reset_index(),
on=['method','mrate','lags','inter_method']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3).query("lags==4")
| 0 |
0.286 |
4 |
linear |
IT-STGCN |
1.329 |
0.120 |
| 1 |
0.286 |
4 |
linear |
STGCN |
1.372 |
0.199 |
| 2 |
0.286 |
4 |
nearest |
IT-STGCN |
1.310 |
0.151 |
| 3 |
0.286 |
4 |
nearest |
STGCN |
1.459 |
0.153 |
WikiMathsDatasetLoader (lags=8)
Baseline
pd.merge(data.query("dataset=='wikimath' and mrate==0").groupby(['lags','nof_filters','method'])['mse'].mean().reset_index(),
data.query("dataset=='wikimath' and mrate==0").groupby(['lags','nof_filters','method'])['mse'].std().reset_index(),
on=['lags','nof_filters','method']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
8 |
64 |
IT-STGCN |
0.626 |
0.015 |
| 1 |
8 |
64 |
STGCN |
0.640 |
0.031 |
Random
pd.merge(data.query("dataset=='wikimath' and mtype=='rand'").groupby(['mrate','lags','method'])['mse'].mean().reset_index(),
data.query("dataset=='wikimath' and mtype=='rand'").groupby(['mrate','lags','method'])['mse'].std().reset_index(),
on=['method','mrate','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
0.3 |
8 |
IT-STGCN |
0.631 |
0.019 |
| 1 |
0.3 |
8 |
STGCN |
0.764 |
0.057 |
| 2 |
0.8 |
8 |
IT-STGCN |
0.920 |
0.069 |
| 3 |
0.8 |
8 |
STGCN |
1.423 |
0.121 |
Block
pd.merge(data.query("dataset=='wikimath' and mtype=='block'").groupby(['mrate','lags','method'])['mse'].mean().reset_index(),
data.query("dataset=='wikimath' and mtype=='block'").groupby(['mrate','lags','method'])['mse'].std().reset_index(),
on=['method','mrate','lags']).rename(columns={'mse_x':'mean','mse_y':'std'})
| 0 |
0.119837 |
8 |
IT-STGCN |
0.627324 |
0.013908 |
| 1 |
0.119837 |
8 |
STGCN |
0.660386 |
0.033577 |
missing values on the same nodes
pd.merge(data_wiki_GSO.groupby(['mrate','lags','method'])['mse'].mean().reset_index(),
data_wiki_GSO.groupby(['mrate','lags','method'])['mse'].std().reset_index(),
on=['method','mrate','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
0.512 |
8 |
IT-STGCN |
0.653 |
0.033 |
| 1 |
0.512 |
8 |
STGCN |
0.963 |
0.098 |
WindmillOutputSmallDatasetLoader (lags=8)
Baseline
pd.merge(data.query("dataset=='windmillsmall' and mrate==0").groupby(['lags','method'])['mse'].mean().reset_index(),
data.query("dataset=='windmillsmall' and mrate==0").groupby(['lags','method'])['mse'].std().reset_index(),
on=['method','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
8 |
IT-STGCN |
1.014 |
0.031 |
| 1 |
8 |
STGCN |
1.023 |
0.055 |
Random
pd.merge(data.query("dataset=='windmillsmall' and mtype=='rand'").groupby(['mrate','lags','method'])['mse'].mean().reset_index(),
data.query("dataset=='windmillsmall' and mtype=='rand'").groupby(['mrate','lags','method'])['mse'].std().reset_index(),
on=['method','mrate','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
0.7 |
8 |
IT-STGCN |
1.142 |
0.021 |
| 1 |
0.7 |
8 |
STGCN |
1.600 |
0.056 |
Block
pd.merge(data.query("dataset=='windmillsmall' and mtype=='block'").groupby(['mrate','lags','method'])['mse'].mean().reset_index(),
data.query("dataset=='windmillsmall' and mtype=='block'").groupby(['mrate','lags','method'])['mse'].std().reset_index(),
on=['method','mrate','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
0.081 |
8 |
IT-STGCN |
0.997 |
0.022 |
| 1 |
0.081 |
8 |
STGCN |
0.989 |
0.009 |
Montevideobus (lags=4)
Baseline
pd.merge(data.query("dataset=='monte' and mrate==0").groupby(['lags','method'])['mse'].mean().reset_index(),
data.query("dataset=='monte' and mrate==0").groupby(['lags','method'])['mse'].std().reset_index(),
on=['method','lags']).rename(columns={'mse_x':'mean','mse_y':'std'}).round(3)
| 0 |
4 |
IT-STGCN |
0.959 |
0.012 |
| 1 |
4 |
STGCN |
0.960 |
0.011 |
Random
pd.merge(data.query("dataset=='monte' and mtype=='rand'").groupby(['mrate','lags','inter_method','method'])['mse'].mean().reset_index(),
data.query("dataset=='monte' and mtype=='rand'").groupby(['mrate','lags','inter_method','method'])['mse'].std().reset_index(),
on=['mrate','inter_method','method','mrate','lags']).rename(columns={'mse_x':'mean','mse_y':'std'})
| 0 |
0.8 |
4 |
nearest |
IT-STGCN |
1.156399 |
0.061898 |
| 1 |
0.8 |
4 |
nearest |
STGCN |
1.133692 |
0.068590 |
Block
pd.merge(data.query("dataset=='monte' and mtype=='block'").groupby(['mrate','lags','inter_method','method'])['mse'].mean().reset_index(),
data.query("dataset=='monte' and mtype=='block'").groupby(['mrate','lags','inter_method','method'])['mse'].std().reset_index(),
on=['method','mrate','inter_method','lags']).rename(columns={'mse_x':'mean','mse_y':'std'})
| 0 |
0.149142 |
4 |
nearest |
IT-STGCN |
0.949276 |
0.007582 |
| 1 |
0.149142 |
4 |
nearest |
STGCN |
0.949673 |
0.005402 |
Check
import itstgcnGConvLSTM
import torch
import numpy as np
import matplotlib.pyplot as plt
class Eval_csy:
def __init__(self,learner,train_dataset):
self.learner = learner
# self.learner.model.eval()
try:self.learner.model.eval()
except:pass
self.train_dataset = train_dataset
self.lags = self.learner.lags
rslt_tr = self.learner(self.train_dataset)
self.X_tr = rslt_tr['X']
self.y_tr = rslt_tr['y']
self.f_tr = torch.concat([self.train_dataset[0].x.T,self.y_tr],axis=0).float()
self.yhat_tr = rslt_tr['yhat']
self.fhat_tr = torch.concat([self.train_dataset[0].x.T,self.yhat_tr],axis=0).float()
import pickle
import pandas as pd
def load_data(fname):
with open(fname, 'rb') as outfile:
data_dict = pickle.load(outfile)
return data_dict
def save_data(data_dict,fname):
with open(fname,'wb') as outfile:
pickle.dump(data_dict,outfile)
T = 500
t = np.arange(T)/T * 5
x = 1*np.sin(2*t)+np.sin(4*t)+1.5*np.sin(7*t)
eps_x = np.random.normal(size=T)*0
y = x.copy()
for i in range(2,T):
y[i] = 0.35*x[i-1] - 0.15*x[i-2] + 0.5*np.cos(0.4*t[i])
eps_y = np.random.normal(size=T)*0
x = x
y = y
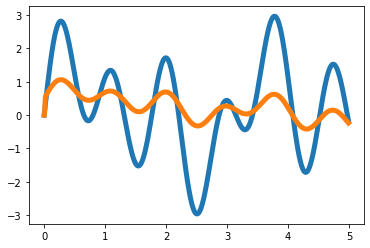
plt.plot(t,x,color='C0',lw=5)
plt.plot(t,x+eps_x,alpha=0.5,color='C0')
plt.plot(t,y,color='C1',lw=5)
plt.plot(t,y+eps_y,alpha=0.5,color='C1')
_node_ids = {'node1':0, 'node2':1}
_FX1 = np.stack([x+eps_x,y+eps_y],axis=1).tolist()
_edges1 = torch.tensor([[0,1]]).tolist()
data_dict1 = {'edges':_edges1, 'node_ids':_node_ids, 'FX':_FX1}
# save_data(data_dict1, './data/toy_example1.pkl')
data1 = pd.DataFrame({'x':x,'y':y,'xer':x,'yer':y})
# save_data(data1, './data/toy_example_true1.csv')
loader1 = itstgcnGConvLSTM.DatasetLoader(data_dict1)
dataset = loader1.get_dataset(lags=2)
mindex = itstgcn.rand_mindex(dataset,mrate=0) dataset_miss = itstgcn.miss(dataset,mindex,mtype=‘rand’)
mindex = [random.sample(range(0, T), int(T*0.8)),[np.array(list(range(20,30)))]]
dataset_miss = itstgcnGConvLSTM.miss(dataset,mindex,mtype='block')
dataset_padded = itstgcnGConvLSTM.padding(dataset_miss,interpolation_method='linear')
- 학습
lrnr_GConvGRU = itstgcnGConvLSTM.StgcnLearner(dataset_padded)
lrnr_GConvGRU.learn(filters=2,epoch=5)
lrnr_GConvGRU1 = itstgcnGConvLSTM.ITStgcnLearner(dataset_padded)
lrnr_GConvGRU1.learn(filters=2,epoch=5)
evtor_GConvGRU = Eval_csy(lrnr_GConvGRU,dataset_padded)
evtor_GConvGRU1 = Eval_csy(lrnr_GConvGRU1,dataset_padded)
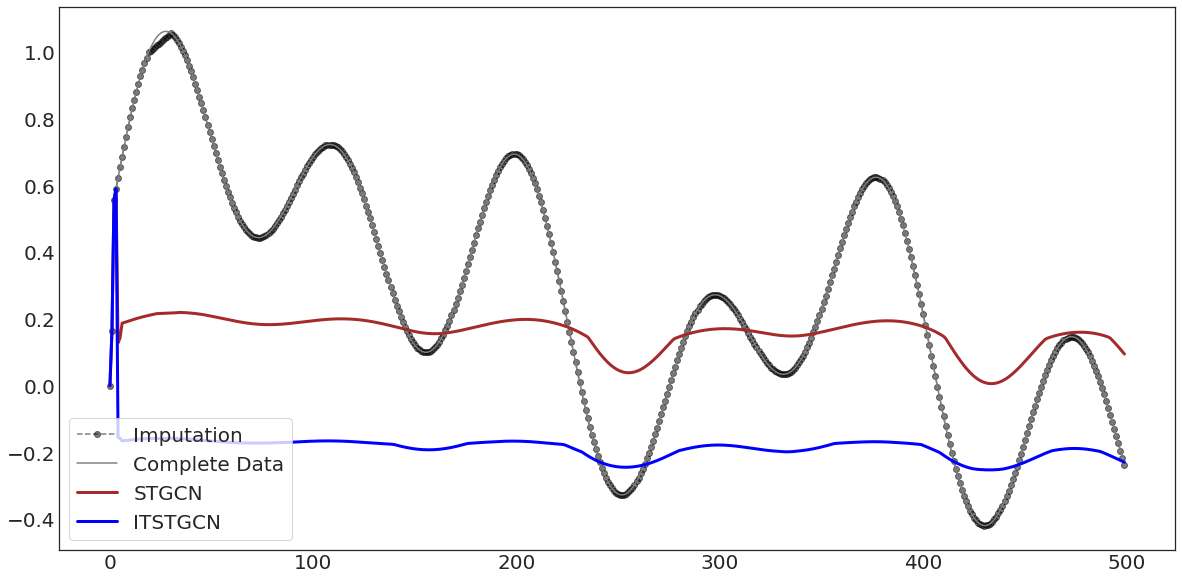
with plt.style.context('seaborn-white'):
fig, ax = plt.subplots(figsize=(20,10))
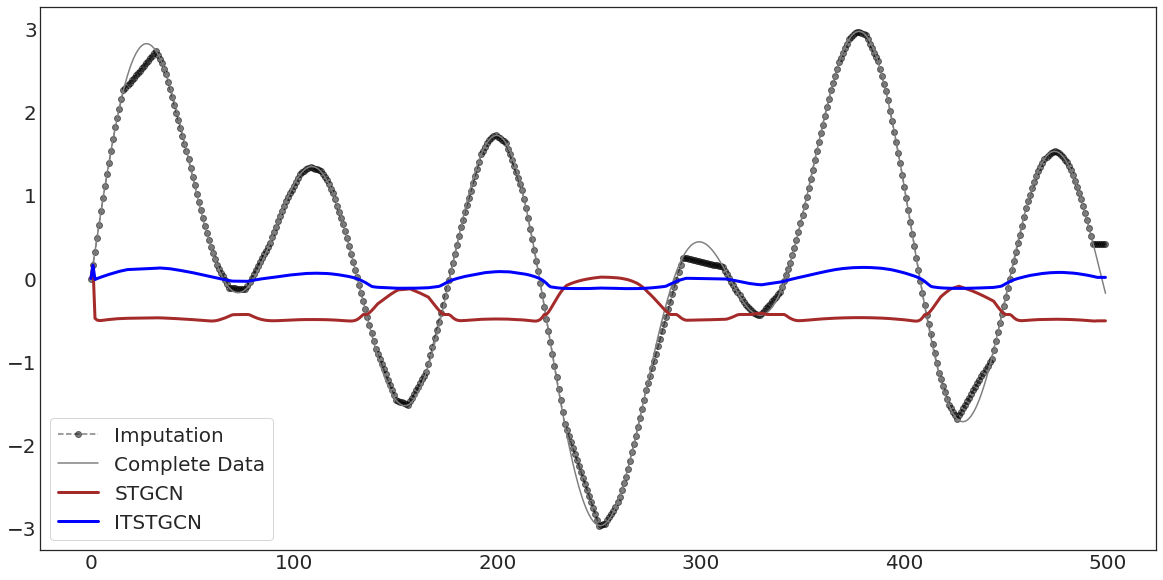
ax.plot(evtor_GConvGRU.f_tr[:,0],'--o',color='black',alpha=0.5,label='Imputation')
ax.plot(data1['x'][:],'-',color='grey',label='Complete Data')
ax.plot(evtor_GConvGRU.fhat_tr[:,0],color='brown',lw=3,label='STGCN')
ax.plot(evtor_GConvGRU1.fhat_tr[:,0],color='blue',lw=3,label='ITSTGCN')
ax.legend(fontsize=20,loc='lower left',facecolor='white', frameon=True)
ax.tick_params(axis='y', labelsize=20)
ax.tick_params(axis='x', labelsize=20)
with plt.style.context('seaborn-white'):
fig, ax = plt.subplots(figsize=(20,10))
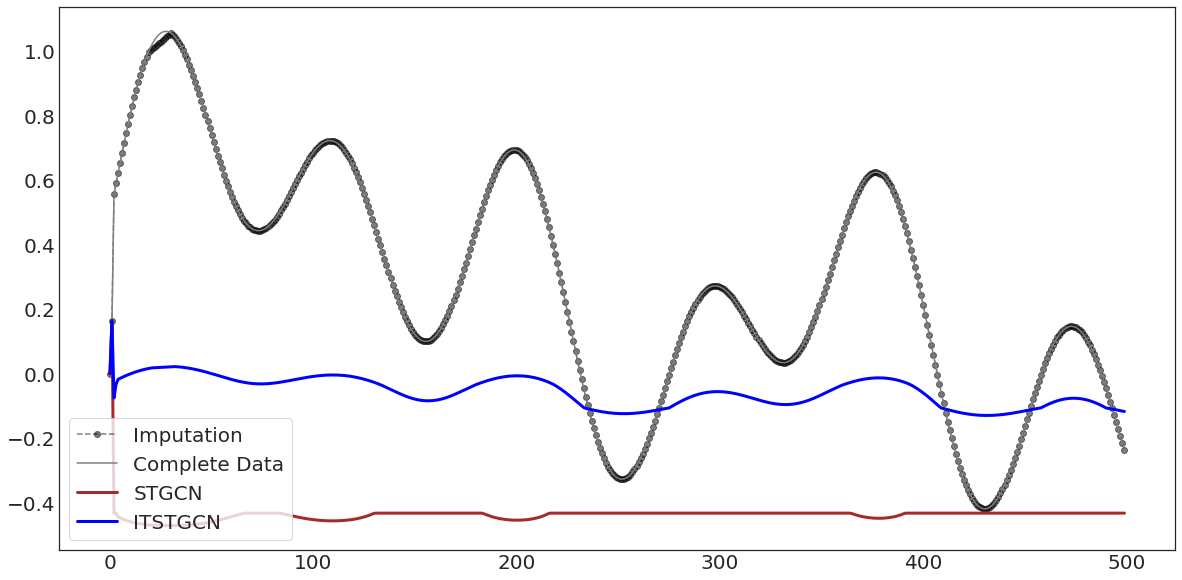
ax.plot(evtor_GConvGRU.f_tr[:,1],'--o',color='black',alpha=0.5,label='Imputation')
ax.plot(data1['y'][:],'-',color='grey',label='Complete Data')
ax.plot(evtor_GConvGRU.fhat_tr[:,1],color='brown',lw=3,label='STGCN')
ax.plot(evtor_GConvGRU1.fhat_tr[:,1],color='blue',lw=3,label='ITSTGCN')
ax.legend(fontsize=20,loc='lower left',facecolor='white', frameon=True)
ax.tick_params(axis='y', labelsize=20)
ax.tick_params(axis='x', labelsize=20)
import itstgcnsnd
import torch
import numpy as np
loader1 = itstgcnsnd.DatasetLoader(data_dict1)
dataset = loader1.get_dataset(lags=4)
mindex = itstgcn.rand_mindex(dataset,mrate=0) dataset_miss = itstgcn.miss(dataset,mindex,mtype=‘rand’)
mindex = [random.sample(range(0, T), int(T*0.7)),[np.array(list(range(20,30)))]]
dataset_miss = itstgcnsnd.miss(dataset,mindex,mtype='block')
dataset_padded = itstgcnsnd.padding(dataset_miss,interpolation_method='linear')
- 학습
lrnr_GConvGRU = itstgcnsnd.StgcnLearner(dataset_padded)
lrnr_GConvGRU.learn(filters=8,epoch=5)
lrnr_GConvGRU1 = itstgcnsnd.ITStgcnLearner(dataset_padded)
lrnr_GConvGRU1.learn(filters=8,epoch=5)
evtor_GConvGRU = Eval_csy(lrnr_GConvGRU,dataset_padded)
evtor_GConvGRU1 = Eval_csy(lrnr_GConvGRU1,dataset_padded)
with plt.style.context('seaborn-white'):
fig, ax = plt.subplots(figsize=(20,10))
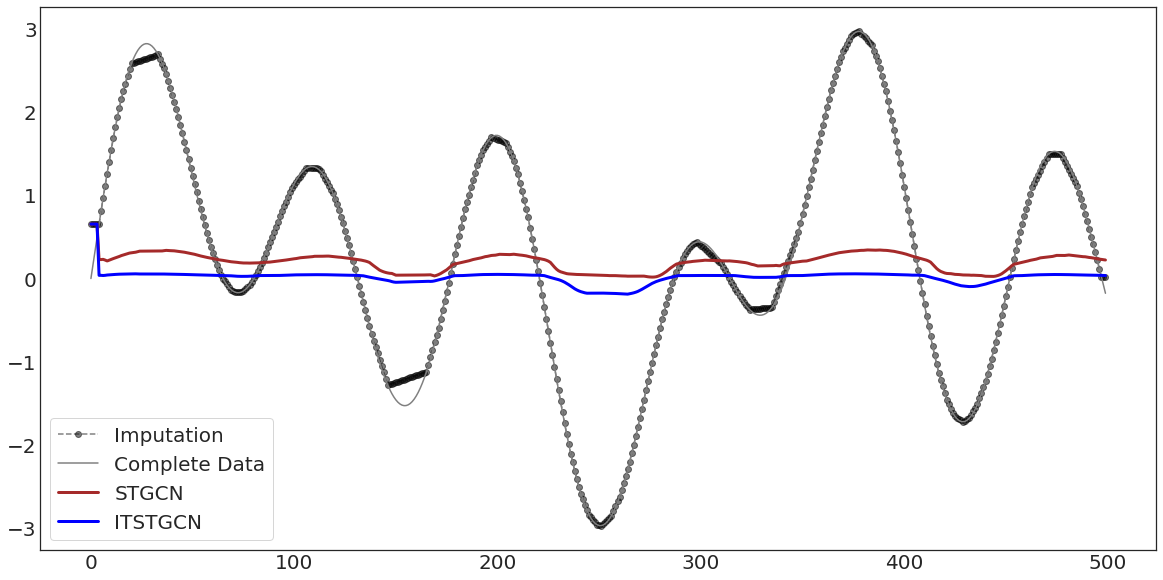
ax.plot(evtor_GConvGRU.f_tr[:,0],'--o',color='black',alpha=0.5,label='Imputation')
ax.plot(data1['x'][:],'-',color='grey',label='Complete Data')
ax.plot(evtor_GConvGRU.fhat_tr[:,0],color='brown',lw=3,label='STGCN')
ax.plot(evtor_GConvGRU1.fhat_tr[:,0],color='blue',lw=3,label='ITSTGCN')
ax.legend(fontsize=20,loc='lower left',facecolor='white', frameon=True)
ax.tick_params(axis='y', labelsize=20)
ax.tick_params(axis='x', labelsize=20)
with plt.style.context('seaborn-white'):
fig, ax = plt.subplots(figsize=(20,10))
ax.plot(evtor_GConvGRU.f_tr[:,1],'--o',color='black',alpha=0.5,label='Imputation')
ax.plot(data1['y'][:],'-',color='grey',label='Complete Data')
ax.plot(evtor_GConvGRU.fhat_tr[:,1],color='brown',lw=3,label='STGCN')
ax.plot(evtor_GConvGRU1.fhat_tr[:,1],color='blue',lw=3,label='ITSTGCN')
ax.legend(fontsize=20,loc='lower left',facecolor='white', frameon=True)
ax.tick_params(axis='y', labelsize=20)
ax.tick_params(axis='x', labelsize=20)
hyperparameter
import itstgcn
data_dict = itstgcn.load_data('./data/fivenodes.pkl')
loader = itstgcn.DatasetLoader(data_dict)
from torch_geometric_temporal.dataset import ChickenpoxDatasetLoader
loader1 = ChickenpoxDatasetLoader()
from torch_geometric_temporal.dataset import PedalMeDatasetLoader
loader2 = PedalMeDatasetLoader()
from torch_geometric_temporal.dataset import WikiMathsDatasetLoader
loader3 = WikiMathsDatasetLoader()
from torch_geometric_temporal.dataset import WindmillOutputSmallDatasetLoader
loader6 = WindmillOutputSmallDatasetLoader()
from torch_geometric_temporal.dataset import MontevideoBusDatasetLoader
loader10 = MontevideoBusDatasetLoader()
try:
from tqdm import tqdm
except ImportError:
def tqdm(iterable):
return iterable
| fivenodes |
GConvGRU |
IT-STGCN |
0.7 |
12 |
2 |
1.167 |
0.059 |
| fivenodes |
GConvGRU |
STGCN |
0.7 |
12 |
2 |
2.077 |
0.252 |
| chickenpox |
GConvGRU |
IT-STGCN |
0.8 |
16 |
4 |
1.586 |
0.199 |
| chickenpox |
GConvGRU |
STGCN |
0.8 |
16 |
4 |
2.529 |
0.292 |
| pedalme |
GConvGRU |
IT-STGCN |
0.6 |
12 |
4 |
1.571 |
0.277 |
| pedalme |
GConvGRU |
STGCN |
0.6 |
12 |
4 |
1.753 |
0.239 |
| wikimath |
GConvGRU |
IT-STGCN |
0.8 |
12 |
8 |
0.687 |
0.021 |
| wikimath |
GConvGRU |
STGCN |
0.8 |
12 |
8 |
0.932 |
0.04 |
| windmillsmall |
GConvGRU |
IT-STGCN |
0.7 |
12 |
8 |
1.180 |
0.035 |
| windmillsmall |
GConvGRU |
STGCN |
0.7 |
12 |
8 |
1.636 |
0.088 |
| monte |
GConvGRU |
IT-STGCN |
0.8 |
12 |
4 |
1.096 |
0.019 |
| monte |
GConvGRU |
STGCN |
0.8 |
12 |
4 |
1.516 |
0.040 |
import torch
import torch.nn.functional as F
from torch_geometric_temporal.nn.recurrent import GConvLSTM
# from torch_geometric_temporal.dataset import ChickenpoxDatasetLoader
from torch_geometric_temporal.signal import temporal_signal_split
# loader1 = ChickenpoxDatasetLoader()
dataset = loader.get_dataset(lags=2)
dataset1 = loader1.get_dataset(lags=4)
dataset2 = loader2.get_dataset(lags=4)
dataset3 = loader3.get_dataset(lags=8)
dataset6 = loader6.get_dataset(lags=8)
dataset10 = loader10.get_dataset(lags=4)
train_dataset, test_dataset = temporal_signal_split(dataset, train_ratio=0.2)
train_dataset1, test_dataset1 = temporal_signal_split(dataset1, train_ratio=0.2)
train_dataset2, test_dataset2 = temporal_signal_split(dataset2, train_ratio=0.2)
train_dataset3, test_dataset3 = temporal_signal_split(dataset3, train_ratio=0.2)
train_dataset6, test_dataset6 = temporal_signal_split(dataset6, train_ratio=0.2)
train_dataset10, test_dataset10 = temporal_signal_split(dataset10, train_ratio=0.2)
class RecurrentGCN(torch.nn.Module):
def __init__(self, node_features, filters):
super(RecurrentGCN, self).__init__()
self.recurrent = GConvLSTM(node_features, filters, 2)
self.linear = torch.nn.Linear(filters, 1)
def forward(self, x, edge_index, edge_weight, h, c):
h_0, c_0 = self.recurrent(x, edge_index, edge_weight, h, c)
h = F.relu(h_0)
h = self.linear(h)
return h, h_0, c_0
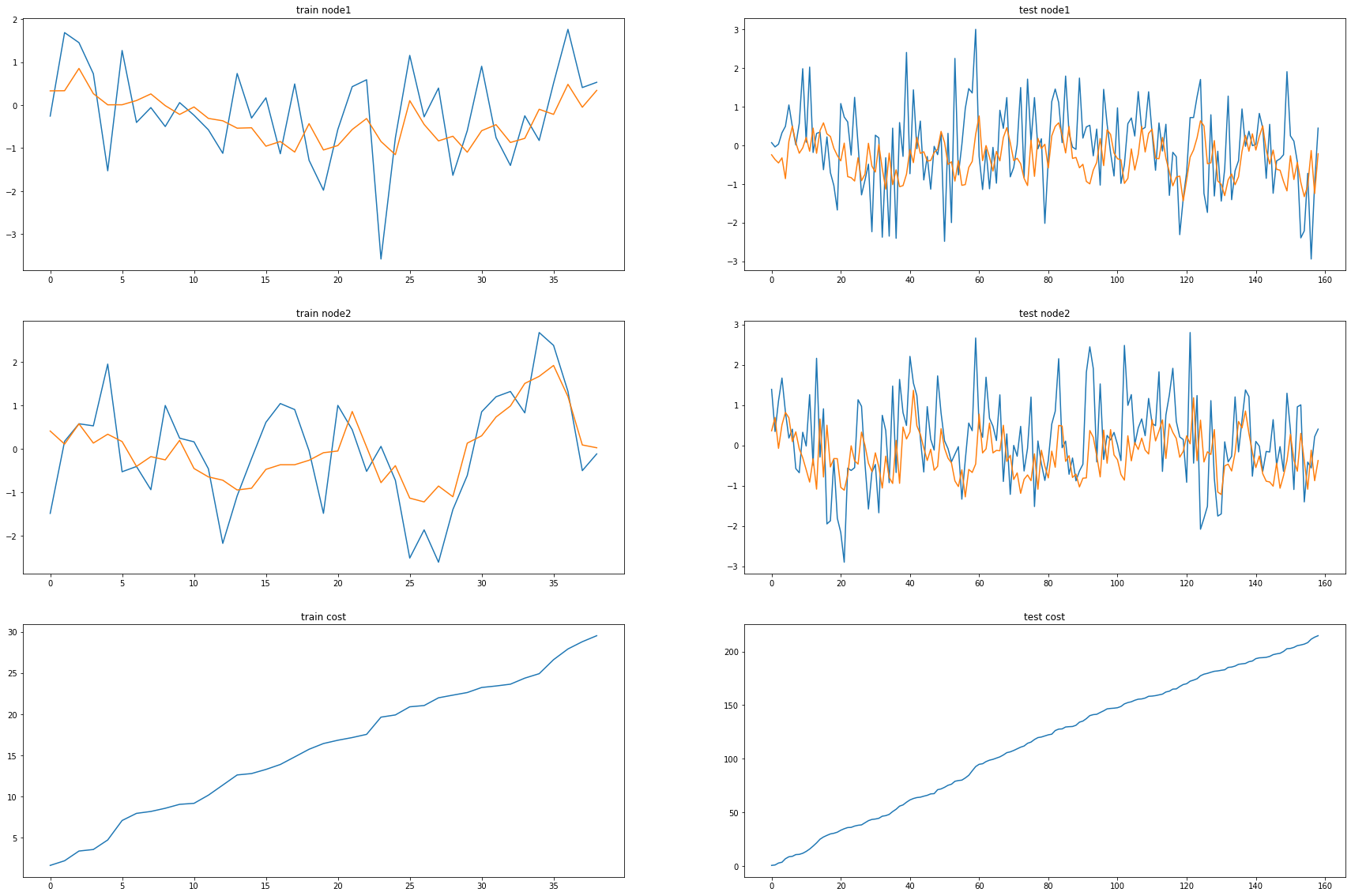
fivenodes Nodes = 2, Filters = 12
model = RecurrentGCN(node_features=2, filters=12)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
model.train()
for epoch in tqdm(range(50)): #200
cost = 0
h, c = None, None
_b = []
_d=[]
for time, snapshot in enumerate(train_dataset):
y_hat, h, c = model(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_b.append(y_hat)
_d.append(cost)
cost = cost / (time+1)
cost.backward()
optimizer.step()
optimizer.zero_grad()
100%|██████████| 50/50 [00:09<00:00, 5.41it/s]
model.eval()
cost = 0
_a=[]
_a1=[]
for time, snapshot in enumerate(test_dataset):
y_hat, h, c = model(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_a.append(y_hat)
_a1.append(cost)
cost = cost / (time+1)
cost = cost.item()
print("MSE: {:.4f}".format(cost))
_c = [_a1[i].detach() for i in range(len(_a1))]
_e = [_d[i].detach() for i in range(len(_d))]
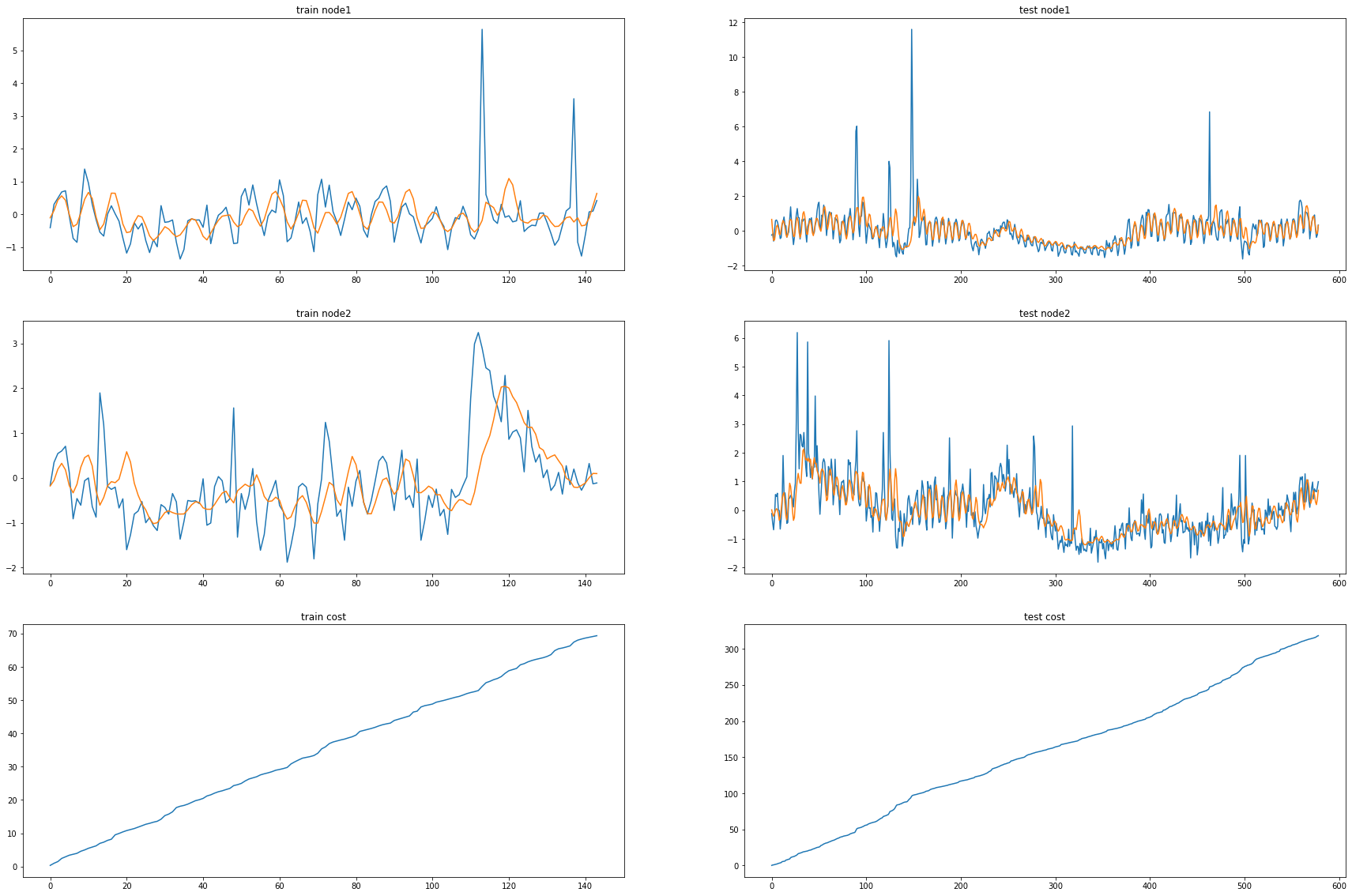
fig, (( ax1,ax2),(ax3,ax4),(ax5,ax6)) = plt.subplots(3,2,figsize=(30,20))
ax1.set_title('train node1')
ax1.plot([train_dataset.targets[i][0] for i in range(train_dataset.snapshot_count)])
ax1.plot(torch.tensor([_b[i].detach()[0] for i in range(train_dataset.snapshot_count)]))
ax2.set_title('test node1')
ax2.plot([test_dataset.targets[i][0] for i in range(test_dataset.snapshot_count)])
ax2.plot(torch.tensor([_a[i].detach()[0] for i in range(test_dataset.snapshot_count)]))
ax3.set_title('train node2')
ax3.plot([train_dataset.targets[i][1] for i in range(train_dataset.snapshot_count)])
ax3.plot(torch.tensor([_b[i].detach()[1] for i in range(train_dataset.snapshot_count)]))
ax4.set_title('test node2')
ax4.plot([test_dataset.targets[i][1] for i in range(test_dataset.snapshot_count)])
ax4.plot(torch.tensor([_a[i].detach()[1] for i in range(test_dataset.snapshot_count)]))
ax5.set_title('train cost')
ax5.plot(_e)
ax6.set_title('test cost')
ax6.plot(_c)
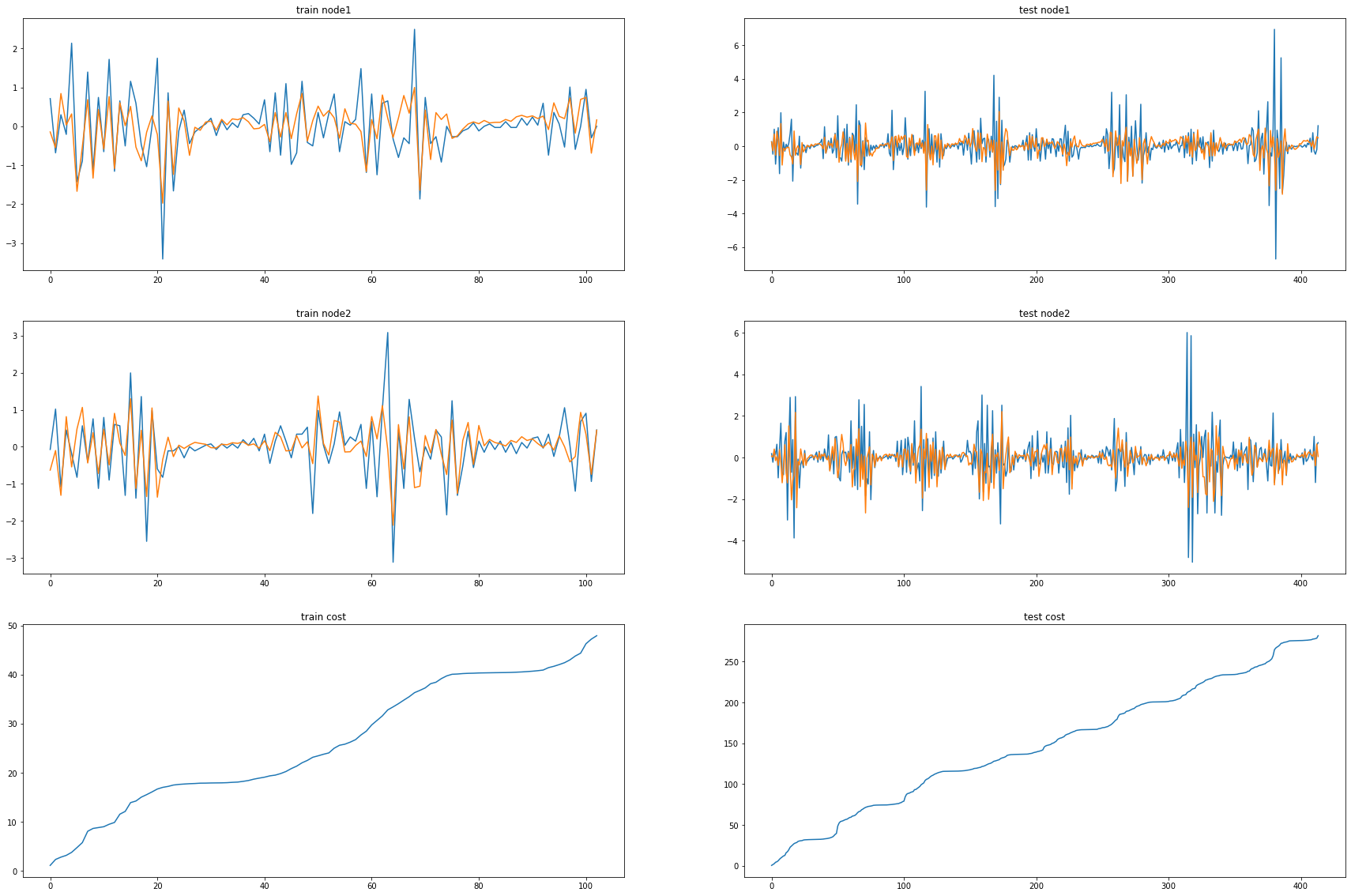
Chickenpox Nodes = 4, Filters = 32
model1 = RecurrentGCN(node_features=4, filters=32)
optimizer1 = torch.optim.Adam(model1.parameters(), lr=0.01)
model1.train()
for epoch in tqdm(range(50)): #200
cost = 0
h, c = None, None
_b = []
_d=[]
for time, snapshot in enumerate(train_dataset1):
y_hat, h, c = model1(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_b.append(y_hat)
_d.append(cost)
cost = cost / (time+1)
cost.backward()
optimizer1.step()
optimizer1.zero_grad()
100%|██████████| 50/50 [01:00<00:00, 1.21s/it]
model1.eval()
cost = 0
_a=[]
_a1=[]
for time, snapshot in enumerate(test_dataset1):
y_hat, h, c = model1(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_a.append(y_hat)
_a1.append(cost)
cost = cost / (time+1)
cost = cost.item()
print("MSE: {:.4f}".format(cost))
_e = [_d[i].detach() for i in range(len(_d))]
_c = [_a1[i].detach() for i in range(len(_a1))]
fig, (( ax1,ax2),(ax3,ax4),(ax5,ax6)) = plt.subplots(3,2,figsize=(30,20))
ax1.set_title('train node1')
ax1.plot([train_dataset1.targets[i][0] for i in range(train_dataset1.snapshot_count)])
ax1.plot(torch.tensor([_b[i].detach()[0] for i in range(train_dataset1.snapshot_count)]))
ax2.set_title('test node1')
ax2.plot([test_dataset1.targets[i][0] for i in range(test_dataset1.snapshot_count)])
ax2.plot(torch.tensor([_a[i].detach()[0] for i in range(test_dataset1.snapshot_count)]))
ax3.set_title('train node2')
ax3.plot([train_dataset1.targets[i][1] for i in range(train_dataset1.snapshot_count)])
ax3.plot(torch.tensor([_b[i].detach()[1] for i in range(train_dataset1.snapshot_count)]))
ax4.set_title('test node2')
ax4.plot([test_dataset1.targets[i][1] for i in range(test_dataset1.snapshot_count)])
ax4.plot(torch.tensor([_a[i].detach()[1] for i in range(test_dataset1.snapshot_count)]))
ax5.set_title('train cost')
ax5.plot(_e)
ax6.set_title('test cost')
ax6.plot(_c)
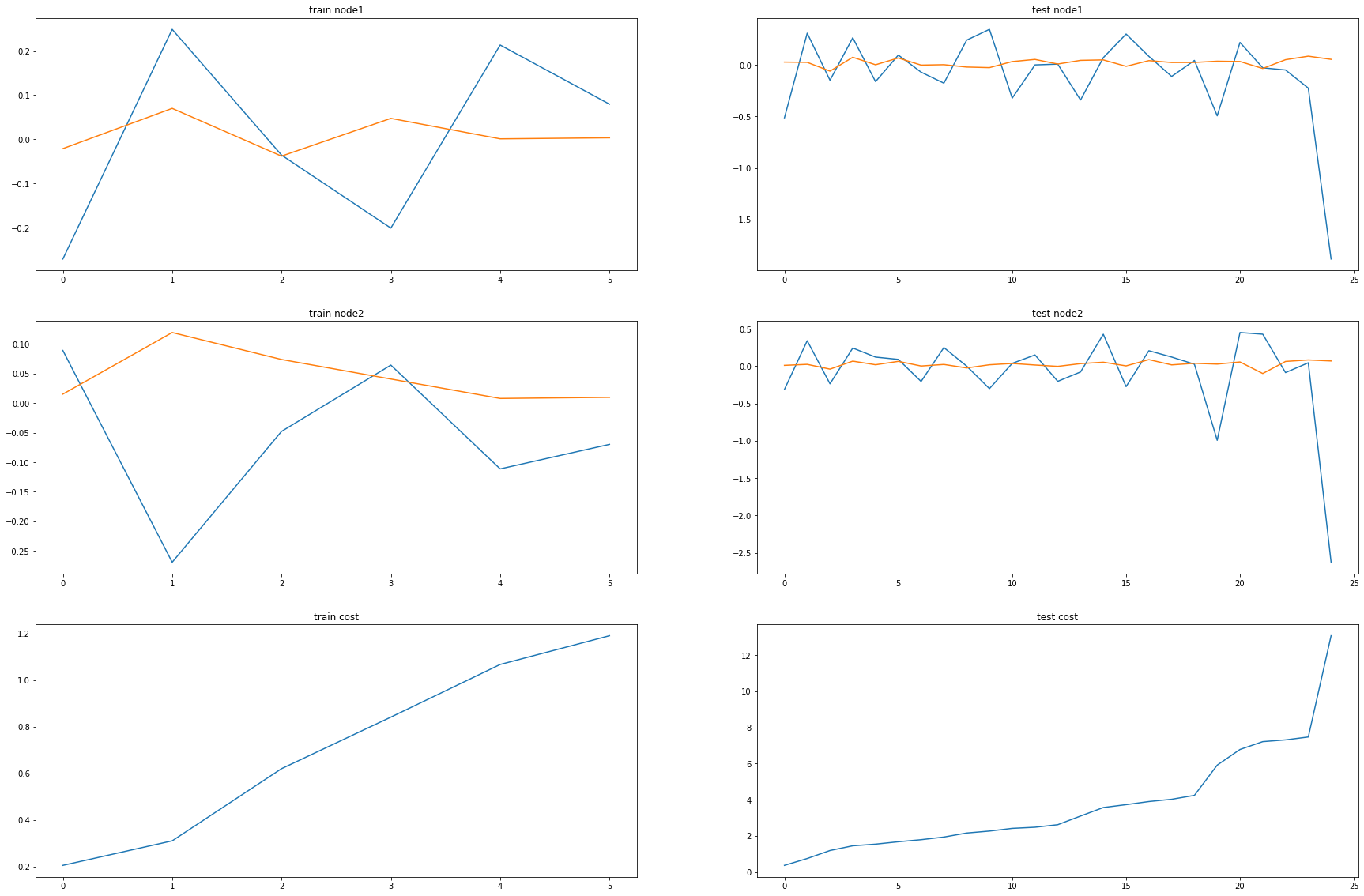
Pedalme Nodes = 4, Filters = 2
model2 = RecurrentGCN(node_features=4, filters=2)
optimizer2 = torch.optim.Adam(model2.parameters(), lr=0.01)
model2.train()
for epoch in tqdm(range(50)): #200
cost = 0
h, c = None, None
_b = []
_d=[]
for time, snapshot in enumerate(train_dataset2):
y_hat, h, c = model2(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_b.append(y_hat)
_d.append(cost)
cost = cost / (time+1)
cost.backward()
optimizer2.step()
optimizer2.zero_grad()
100%|██████████| 50/50 [00:03<00:00, 14.44it/s]
model2.eval()
cost = 0
_a=[]
_a1=[]
for time, snapshot in enumerate(test_dataset2):
y_hat, h, c = model2(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_a.append(y_hat)
_a1.append(cost)
cost = cost / (time+1)
cost = cost.item()
print("MSE: {:.4f}".format(cost))
_e = [_d[i].detach() for i in range(len(_d))]
_c = [_a1[i].detach() for i in range(len(_a1))]
fig, (( ax1,ax2),(ax3,ax4),(ax5,ax6)) = plt.subplots(3,2,figsize=(30,20))
ax1.set_title('train node1')
ax1.plot([train_dataset2.targets[i][0] for i in range(train_dataset2.snapshot_count)])
ax1.plot(torch.tensor([_b[i].detach()[0] for i in range(train_dataset2.snapshot_count)]))
ax2.set_title('test node1')
ax2.plot([test_dataset2.targets[i][0] for i in range(test_dataset2.snapshot_count)])
ax2.plot(torch.tensor([_a[i].detach()[0] for i in range(test_dataset2.snapshot_count)]))
ax3.set_title('train node2')
ax3.plot([train_dataset2.targets[i][1] for i in range(train_dataset2.snapshot_count)])
ax3.plot(torch.tensor([_b[i].detach()[1] for i in range(train_dataset2.snapshot_count)]))
ax4.set_title('test node2')
ax4.plot([test_dataset2.targets[i][1] for i in range(test_dataset2.snapshot_count)])
ax4.plot(torch.tensor([_a[i].detach()[1] for i in range(test_dataset2.snapshot_count)]))
ax5.set_title('train cost')
ax5.plot(_e)
ax6.set_title('test cost')
ax6.plot(_c)
Wikimaths Nodes = 8, Filters = 64
model3 = RecurrentGCN(node_features=8, filters=64)
optimizer3 = torch.optim.Adam(model3.parameters(), lr=0.01)
model3.train()
for epoch in tqdm(range(10)): #200
cost = 0
h, c = None, None
_b = []
_d=[]
for time, snapshot in enumerate(train_dataset3):
y_hat, h, c = model3(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_b.append(y_hat)
_d.append(cost)
cost = cost / (time+1)
cost.backward()
optimizer3.step()
optimizer3.zero_grad()
100%|██████████| 10/10 [00:45<00:00, 4.56s/it]
model3.eval()
cost = 0
_a=[]
_a1=[]
for time, snapshot in enumerate(test_dataset3):
y_hat, h, c = model3(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_a.append(y_hat)
_a1.append(cost)
cost = cost / (time+1)
cost = cost.item()
print("MSE: {:.4f}".format(cost))
_e = [_d[i].detach() for i in range(len(_d))]
_c = [_a1[i].detach() for i in range(len(_a1))]
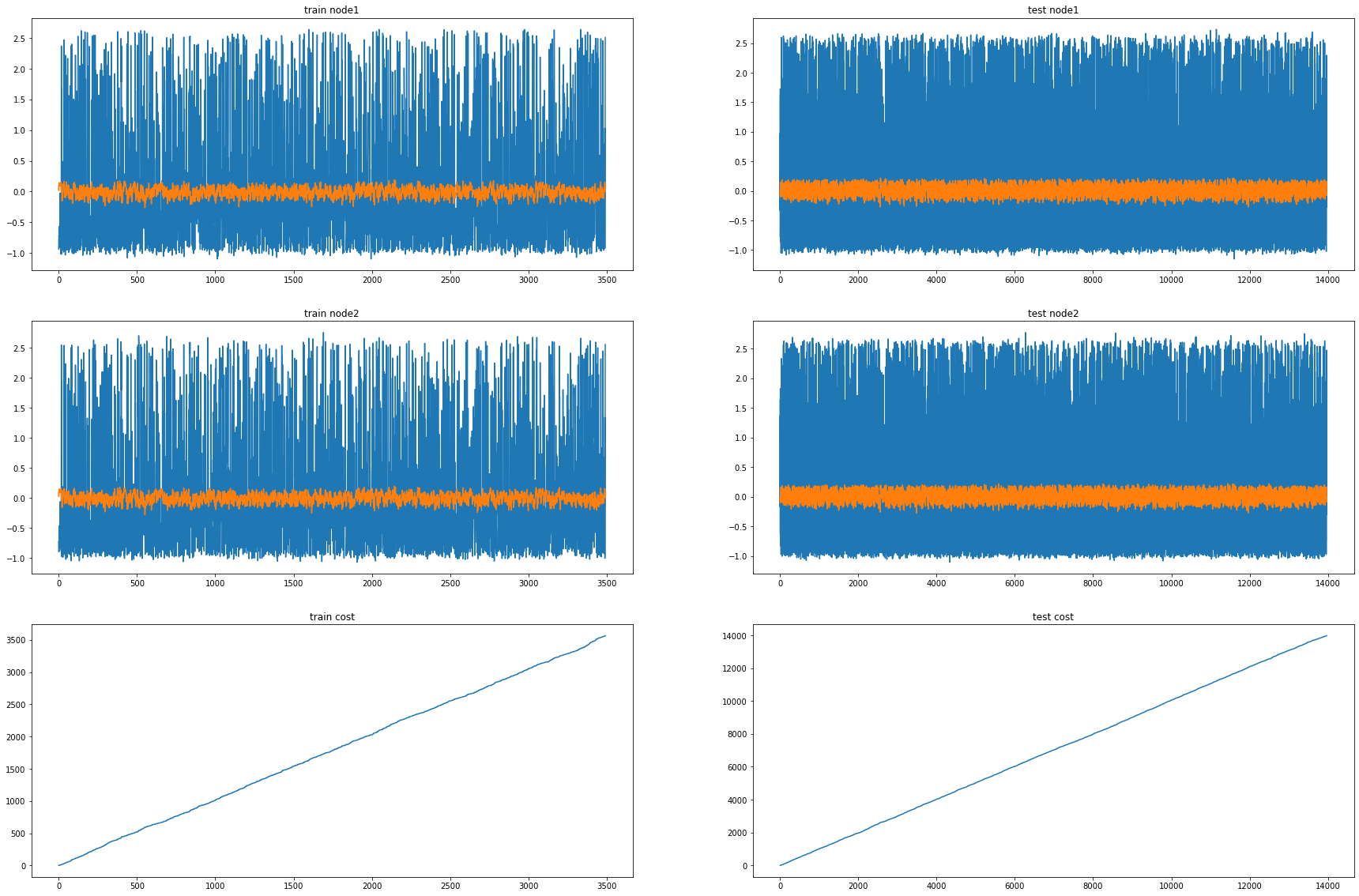
fig, (( ax1,ax2),(ax3,ax4),(ax5,ax6)) = plt.subplots(3,2,figsize=(30,20))
ax1.set_title('train node1')
ax1.plot([train_dataset3.targets[i][0] for i in range(train_dataset3.snapshot_count)])
ax1.plot(torch.tensor([_b[i].detach()[0] for i in range(train_dataset3.snapshot_count)]))
ax2.set_title('test node1')
ax2.plot([test_dataset3.targets[i][0] for i in range(test_dataset3.snapshot_count)])
ax2.plot(torch.tensor([_a[i].detach()[0] for i in range(test_dataset3.snapshot_count)]))
ax3.set_title('train node2')
ax3.plot([train_dataset3.targets[i][1] for i in range(train_dataset3.snapshot_count)])
ax3.plot(torch.tensor([_b[i].detach()[1] for i in range(train_dataset3.snapshot_count)]))
ax4.set_title('test node2')
ax4.plot([test_dataset3.targets[i][1] for i in range(test_dataset3.snapshot_count)])
ax4.plot(torch.tensor([_a[i].detach()[1] for i in range(test_dataset3.snapshot_count)]))
ax5.set_title('train cost')
ax5.plot(_e)
ax6.set_title('test cost')
ax6.plot(_c)
Windmillsmall Nodes = 8, Filters = 16
model6 = RecurrentGCN(node_features=8, filters=16)
optimizer6 = torch.optim.Adam(model6.parameters(), lr=0.01)
model6.train()
for epoch in tqdm(range(10)): #200
cost = 0
h, c = None, None
_b = []
_d=[]
for time, snapshot in enumerate(train_dataset6):
y_hat, h, c = model6(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_b.append(y_hat)
_d.append(cost)
cost = cost / (time+1)
cost.backward()
optimizer6.step()
optimizer6.zero_grad()
100%|██████████| 10/10 [05:36<00:00, 33.66s/it]
model6.eval()
cost = 0
_a=[]
_a1=[]
for time, snapshot in enumerate(test_dataset6):
y_hat, h, c = model6(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_a.append(y_hat)
_a1.append(cost)
cost = cost / (time+1)
cost = cost.item()
print("MSE: {:.4f}".format(cost))
_e = [_d[i].detach() for i in range(len(_d))]
_c = [_a1[i].detach() for i in range(len(_a1))]
fig, (( ax1,ax2),(ax3,ax4),(ax5,ax6)) = plt.subplots(3,2,figsize=(30,20))
ax1.set_title('train node1')
ax1.plot([train_dataset6.targets[i][0] for i in range(train_dataset6.snapshot_count)])
ax1.plot(torch.tensor([_b[i].detach()[0] for i in range(train_dataset6.snapshot_count)]))
ax2.set_title('test node1')
ax2.plot([test_dataset6.targets[i][0] for i in range(test_dataset6.snapshot_count)])
ax2.plot(torch.tensor([_a[i].detach()[0] for i in range(test_dataset6.snapshot_count)]))
ax3.set_title('train node2')
ax3.plot([train_dataset6.targets[i][1] for i in range(train_dataset6.snapshot_count)])
ax3.plot(torch.tensor([_b[i].detach()[1] for i in range(train_dataset6.snapshot_count)]))
ax4.set_title('test node2')
ax4.plot([test_dataset6.targets[i][1] for i in range(test_dataset6.snapshot_count)])
ax4.plot(torch.tensor([_a[i].detach()[1] for i in range(test_dataset6.snapshot_count)]))
ax5.set_title('train cost')
ax5.plot(_e)
ax6.set_title('test cost')
ax6.plot(_c)
Monte Nodes = 4, Filters = 12
model10 = RecurrentGCN(node_features=4, filters=12)
optimizer10 = torch.optim.Adam(model10.parameters(), lr=0.01)
model10.train()
for epoch in tqdm(range(50)): #200
cost = 0
h, c = None, None
_b = []
_d=[]
for time, snapshot in enumerate(train_dataset10):
y_hat, h, c = model10(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_b.append(y_hat)
_d.append(cost)
cost = cost / (time+1)
cost.backward()
optimizer10.step()
optimizer10.zero_grad()
100%|██████████| 50/50 [03:16<00:00, 3.94s/it]
model10.eval()
cost = 0
_a=[]
_a1=[]
for time, snapshot in enumerate(test_dataset10):
y_hat, h, c = model10(snapshot.x, snapshot.edge_index, snapshot.edge_attr, h, c)
y_hat = y_hat.reshape(-1)
cost = cost + torch.mean((y_hat-snapshot.y)**2)
_a.append(y_hat)
_a1.append(cost)
cost = cost / (time+1)
cost = cost.item()
print("MSE: {:.4f}".format(cost))
_e = [_d[i].detach() for i in range(len(_d))]
_c = [_a1[i].detach() for i in range(len(_a1))]
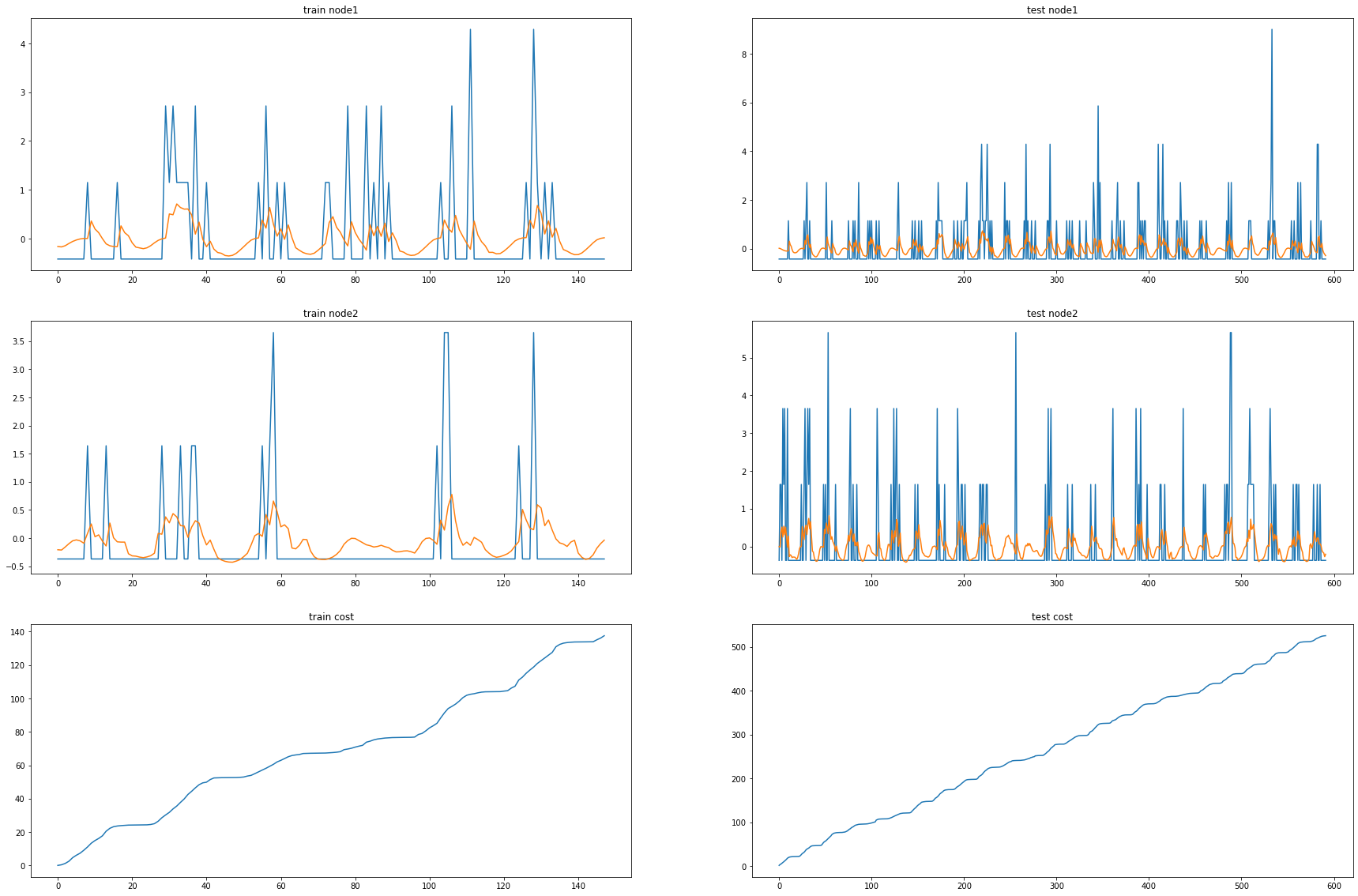
fig, (( ax1,ax2),(ax3,ax4),(ax5,ax6)) = plt.subplots(3,2,figsize=(30,20))
ax1.set_title('train node1')
ax1.plot([train_dataset10.targets[i][0] for i in range(train_dataset10.snapshot_count)])
ax1.plot(torch.tensor([_b[i].detach()[0] for i in range(train_dataset10.snapshot_count)]))
ax2.set_title('test node1')
ax2.plot([test_dataset10.targets[i][0] for i in range(test_dataset10.snapshot_count)])
ax2.plot(torch.tensor([_a[i].detach()[0] for i in range(test_dataset10.snapshot_count)]))
ax3.set_title('train node2')
ax3.plot([train_dataset10.targets[i][10] for i in range(train_dataset10.snapshot_count)])
ax3.plot(torch.tensor([_b[i].detach()[10] for i in range(train_dataset10.snapshot_count)]))
ax4.set_title('test node2')
ax4.plot([test_dataset10.targets[i][10] for i in range(test_dataset10.snapshot_count)])
ax4.plot(torch.tensor([_a[i].detach()[10] for i in range(test_dataset10.snapshot_count)]))
ax5.set_title('train cost')
ax5.plot(_e)
ax6.set_title('test cost')
ax6.plot(_c)