import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import animation
# torch
import torch
import torch.nn.functional as F
from torch_geometric_temporal.nn.recurrent import GConvGRU
# scipy
from scipy.interpolate import interp1d
# utils
import time
import pickle
from tqdm import tqdm
# rpy2
import rpy2
import rpy2.robjects as ro
from rpy2.robjects.vectors import FloatVector
from rpy2.robjects.packages import importr
import copyClass of Method(WikiMath) lag 4
ST-GCN
ST-GCN Dataset WikiMathsDatasetLoader
import
class RecurrentGCN(torch.nn.Module):
def __init__(self, node_features, filters):
super(RecurrentGCN, self).__init__()
self.recurrent = GConvGRU(node_features, filters, 2)
self.linear = torch.nn.Linear(filters, 1)
def forward(self, x, edge_index, edge_weight):
h = self.recurrent(x, edge_index, edge_weight)
h = F.relu(h)
h = self.linear(h)
return hmy functions
def load_data(fname):
with open(fname, 'rb') as outfile:
data_dict = pickle.load(outfile)
return data_dictdef save_data(data_dict,fname):
with open(fname,'wb') as outfile:
pickle.dump(data_dict,outfile)def plot(f,*args,t=None,h=2.5,**kwargs):
T,N = f.shape
if t == None: t = range(T)
fig = plt.figure()
ax = fig.subplots(N,1)
for n in range(N):
ax[n].plot(t,f[:,n],*args,**kwargs)
ax[n].set_title('node='+str(n))
fig.set_figheight(N*h)
fig.tight_layout()
plt.close()
return figdef plot_add(fig,f,*args,t=None,**kwargs):
T = f.shape[0]
N = f.shape[1]
if t == None: t = range(T)
ax = fig.get_axes()
for n in range(N):
ax[n].plot(t,f[:,n],*args,**kwargs)
return figdef make_Psi(T):
W = np.zeros((T,T))
for i in range(T):
for j in range(T):
if i==j :
W[i,j] = 0
elif np.abs(i-j) <= 1 :
W[i,j] = 1
d = np.array(W.sum(axis=1))
D = np.diag(d)
L = np.array(np.diag(1/np.sqrt(d)) @ (D-W) @ np.diag(1/np.sqrt(d)))
lamb, Psi = np.linalg.eigh(L)
return Psiebayesthresh = importr('EbayesThresh').ebayesthreshdef trim(f):
f = np.array(f)
if len(f.shape)==1: f = f.reshape(-1,1)
T,N = f.shape
Psi = make_Psi(T)
fbar = Psi.T @ f # apply dft
fbar_threshed = np.stack([ebayesthresh(FloatVector(fbar[:,i])) for i in range(N)],axis=1)
fhat = Psi @ fbar_threshed # inverse dft
return fhatdef update_from_freq_domain(signal, missing_index):
signal = np.array(signal)
T,N = signal.shape
signal_trimed = trim(signal)
for i in range(N):
signal[missing_index[i],i] = signal_trimed[missing_index[i],i]
return signalData
from torch_geometric_temporal.dataset import WikiMathsDatasetLoader
from torch_geometric_temporal.signal import temporal_signal_splitloader = WikiMathsDatasetLoader()dataset = loader.get_dataset(lags=4)train_dataset, test_dataset = temporal_signal_split(dataset, train_ratio=0.8)Train
data_train=[]
for time, snapshot in enumerate(train_dataset):
data_train.append([time,snapshot])data_train[0][1].x.shape,data_train[0][1].y.shape,data_train[0][1].edge_index.shape,data_train[0][1].edge_attr.shape(torch.Size([1068, 4]),
torch.Size([1068]),
torch.Size([2, 27079]),
torch.Size([27079]))time580T_train = time
N = len(data_train[0][1].x)edge_index = data_train[0][1].edge_index
edge_attr = data_train[0][1].edge_attrx_train = []
for i in range(time):
x_train.append(data_train[i][1].x)data_tensor = torch.Tensor()
# Iterate over the data points of the dataset
for i in x_train:
# Concatenate the data point to the tensor
data_tensor = torch.cat((data_tensor, i), dim=0)
x_train = data_tensor.reshape(time,1068,-1)
x_train.shapetorch.Size([580, 1068, 4])y_train = []
for i in range(time):
y_train.append(data_train[i][1].y)data_tensor = torch.Tensor()
# Iterate over the data points of the dataset
for i in y_train:
# Concatenate the data point to the tensor
data_tensor = torch.cat((data_tensor, i), dim=0)
y_train = data_tensor.reshape(time,1068)
y_train.shapetorch.Size([580, 1068])x_train.shape, y_train.shape(torch.Size([580, 1068, 4]), torch.Size([580, 1068]))Test
data_test=[]
for time, snapshot in enumerate(test_dataset):
data_test.append([time,snapshot])data_test[0][1].x.shape,data_test[0][1].y.shape,data_test[0][1].edge_index.shape,data_test[0][1].edge_attr.shape(torch.Size([1068, 4]),
torch.Size([1068]),
torch.Size([2, 27079]),
torch.Size([27079]))time145T_test = timex_test = []
for i in range(time):
x_test.append(data_test[i][1].x)data_tensor = torch.Tensor()
# Iterate over the data points of the dataset
for i in x_test:
# Concatenate the data point to the tensor
data_tensor = torch.cat((data_tensor, i), dim=0)
x_test = data_tensor.reshape(time,1068,-1)
x_test.shapetorch.Size([145, 1068, 4])y_test = []
for i in range(time):
y_test.append(data_test[i][1].y)data_tensor = torch.Tensor()
# Iterate over the data points of the dataset
for i in y_test:
# Concatenate the data point to the tensor
data_tensor = torch.cat((data_tensor, i), dim=0)
y_test = data_tensor.reshape(time,1068)
y_test.shapetorch.Size([145, 1068])x_test.shape, y_test.shape(torch.Size([145, 1068, 4]), torch.Size([145, 1068]))data 정리
- 데이터정리
T_test,T_train,N(145, 580, 1068)E = edge_index;Etensor([[ 0, 0, 0, ..., 1056, 1063, 1065],
[ 1, 2, 3, ..., 1059, 1064, 1066]])edge_index = Eedge_attrtensor([1., 4., 2., ..., 1., 1., 2.])- train / test
x_train.shape,y_train.shape,x_test.shape,y_test.shape,edge_index.shape,edge_attr.shape(torch.Size([580, 1068, 4]),
torch.Size([580, 1068]),
torch.Size([145, 1068, 4]),
torch.Size([145, 1068]),
torch.Size([2, 27079]),
torch.Size([27079]))fig = plot(y_train[:,:5],'--o',label='train',color='C0')
fig = plot_add(fig,y_test[:,:5],'--o',label='test',color='C1',t=range(581,726))
ax = fig.get_axes()
for a in ax:
a.legend()
fig.set_figwidth(10)
fig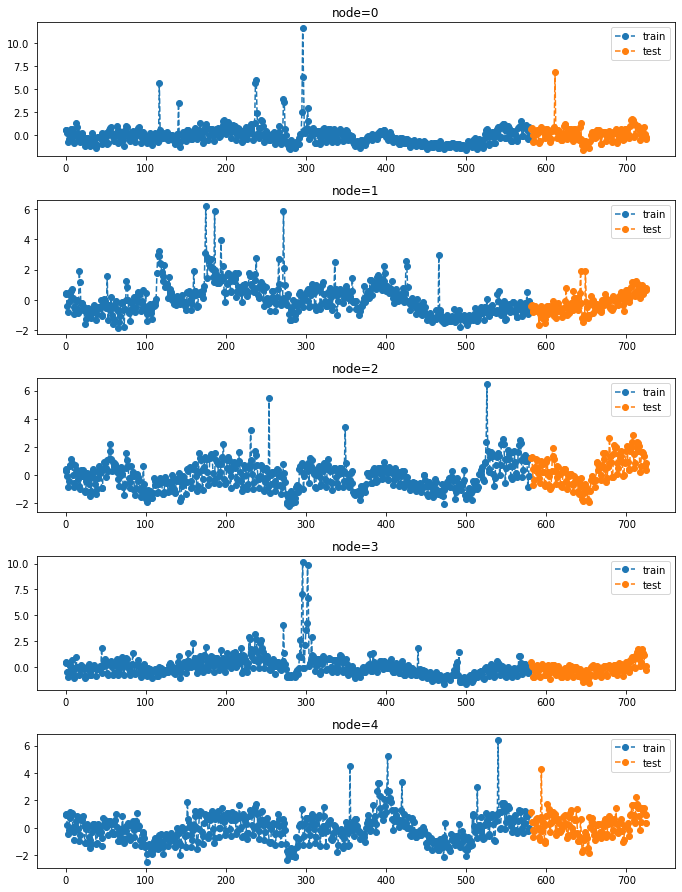
Random Missing Values
class Missing:
def __init__(self,df):
self.df = df
self.N = N
self.number = []
def miss(self,percent=0.5):
self.missing = copy.deepcopy(self.df)
self.percent = percent
for i in range(self.N):
#self.seed = np.random.choice(1000,1,replace=False)
#np.random.seed(self.seed)
self.number.append(np.random.choice(int(len(self.df))-10,int(len(self.df)*self.percent),replace=False))
self.missing[self.number[i],i] = float('nan')
def first_mean(self):
self.train_mean = np.array(copy.deepcopy(self.missing))
for i in range(self.N):
self.train_mean[self.number[i],i] = np.nanmean(self.missing[:,i])
def second_linear(self):
self.train_linear = pd.DataFrame(self.missing.tolist())
self.train_linear.interpolate(method='linear', inplace=True)
self.train_linear = self.train_linear.fillna(0)
self.train_linear = np.array(self.train_linear).reshape(int(len(self.df)),N)- 30% 결측치 발생
x_train_f = torch.concat([x_train[:-1,:,0], x_train[-1,:,:].T])x_test_f = torch.concat([x_test[:-1,:,0], x_train[-1,:,:].T])_zero = Missing(x_train_f)
_zero.miss(percent = 0.3)fig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.plot(_zero.missing[:,i],'o',color='C0',label='observed')
a.plot(_zero.number[i],x_train_f[_zero.number[i],i],'x',color='C1',label='missing')
a.legend()
fig.set_figwidth(10)
fig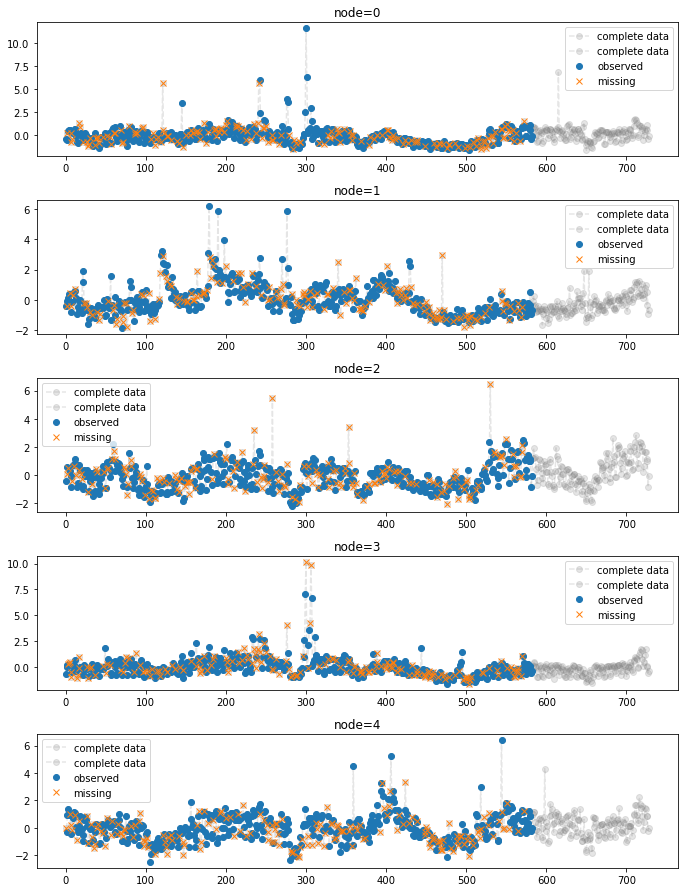
- 결측치를 평균으로 보간
_zero.first_mean()
fig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.plot(_zero.missing[:,i],'o',color='C0',label='observed')
a.plot(_zero.number[i],x_train_f[:,:][_zero.number[i],i],'x',color='C1',label='missing')
a.plot(_zero.train_mean[:,i],'-',color='red',label='padding mean')
a.legend()
fig.set_figwidth(15)
fig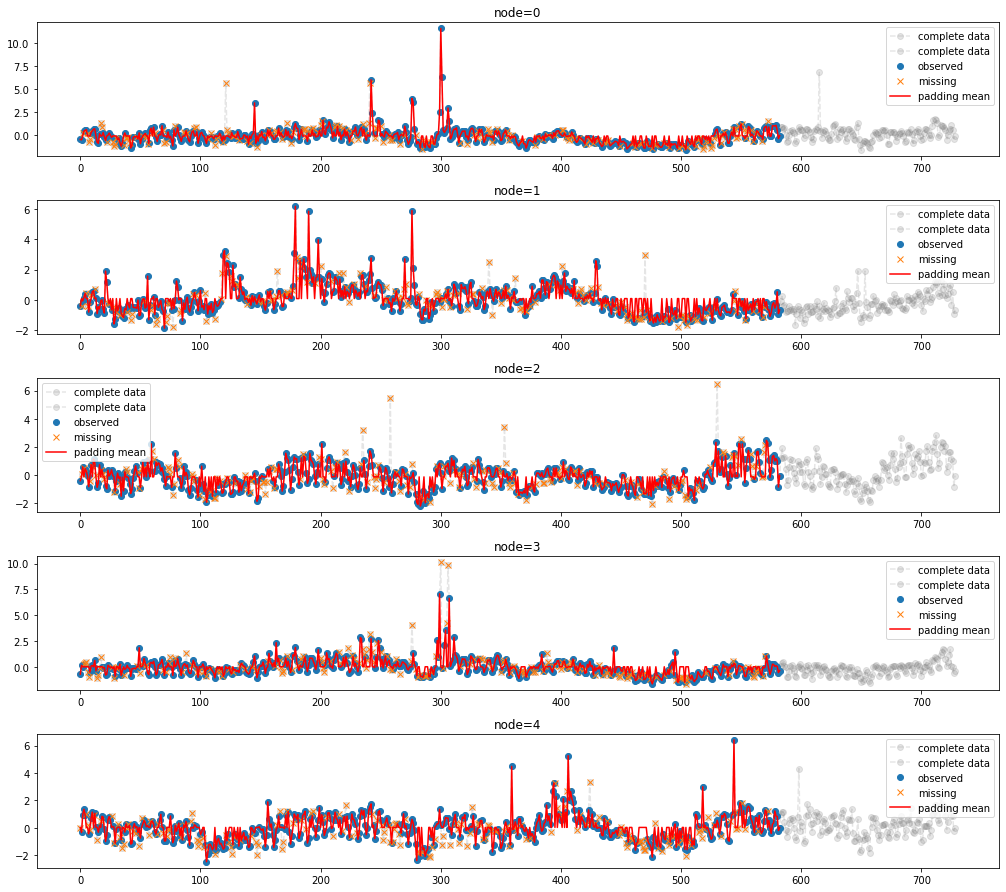
- 결측치를 linear interpolation
_zero.second_linear()
fig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.plot(_zero.missing[:,i],'o',color='C0',label='observed')
a.plot(_zero.number[i],x_train_f[:,:][_zero.number[i],i],'x',color='C1',label='missing')
a.plot(_zero.train_linear[:,i],'-',color='red',label='linear interpolation')
a.legend()
fig.set_figwidth(15)
fig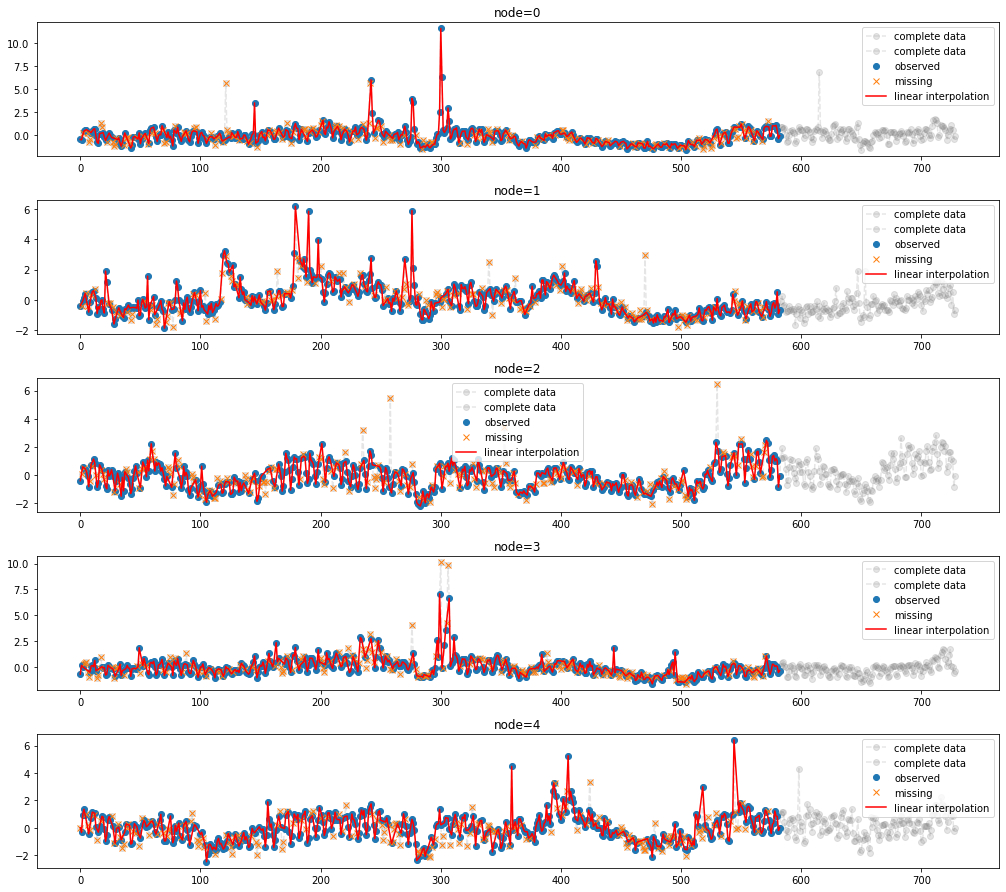
Enhencement of STGCN
시나리오1 (Baseline)
시나리오1
- missing rate: 0%
- 보간방법: None
STGCN 으로 적합 + 예측
X = torch.tensor(np.stack([x_train_f[i:(T_train-4+i),:] for i in range(4)],axis = -1)).float()
y = x_train_f[4:T_train,:].reshape(T_train-4,N,-1).float()XX = x_test
yy = y_testnet = RecurrentGCN(node_features=4, filters=4)
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
net.train()
for epoch in tqdm(range(50)):
for time, (xt,yt) in enumerate(zip(X,y)):
yt_hat = net(xt, edge_index, edge_attr)
cost = torch.mean((yt_hat-yt)**2)
cost.backward()
optimizer.step()
optimizer.zero_grad()100%|██████████| 50/50 [05:47<00:00, 6.96s/it]yhat = torch.stack([net(xt, edge_index, edge_attr) for xt in X]).detach().numpy()
yyhat = torch.stack([net(xt, edge_index, edge_attr) for xt in XX]).detach().numpy()stgcn_train = yhat.squeeze() # stgcn은 stgcn에 의한 적합결과를 의미함
stgcn_test = yyhat.squeeze() train_mse_eachnode_stgcn = (((y.squeeze()-yhat.squeeze()).squeeze())**2).mean(axis=0)
train_mse_total_stgcn = (((y.squeeze()-yhat.squeeze()).squeeze())**2).mean()
test_mse_eachnode_stgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean(axis=0)
test_mse_total_stgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean()GNAR 으로 적합 + 예측
-
%load_ext rpy2.ipython%%R
library(GNAR)
library(igraph)R[write to console]: Loading required package: igraph
R[write to console]:
Attaching package: ‘igraph’
R[write to console]: The following objects are masked from ‘package:stats’:
decompose, spectrum
R[write to console]: The following object is masked from ‘package:base’:
union
R[write to console]: Loading required package: wordcloud
R[write to console]: Loading required package: RColorBrewer
Edge = np.array(edge_index)
X_gnar = np.array(x_train_f)w=np.zeros((1068,1068))for k in range(27079):
w[edge_index[0][k],edge_index[1][k]] = 1%R -i X_gnar
%R -i w
%R -i T_test%%R
wikiNet <- matrixtoGNAR(w)%%R
answer <- GNARfit(vts = X_gnar, net = wikiNet, alphaOrder = 4, betaOrder = c(1,1,1,1))
prediction <- predict(answer,n.ahead=T_test)%%R
gnar_train <- residuals(answer)
gnar_test <- prediction%R -o gnar_train
%R -o gnar_testtrain_mse_eachnode_gnar = (gnar_train**2).mean(axis=0)
train_mse_total_gnar = (gnar_train**2).mean()
test_mse_eachnode_gnar = ((yy-gnar_test)**2).mean(axis=0)
test_mse_total_gnar = ((yy-gnar_test)**2).mean()결과시각화
fig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,h=5)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.set_title('node{0} \n STGCN: mse(train) = {1:.2f}, mse(test) = {2:.2f} \n GNAR: mse(train) = {3:.2f}, mse(test) = {4:.2f}'.format(i,train_mse_eachnode_stgcn[i],test_mse_eachnode_stgcn[i],train_mse_eachnode_gnar[i],test_mse_eachnode_gnar[i]))
a.plot(range(4,580),stgcn_train[:,i],label='STCGCN (train)',color='C0')
a.plot(range(583,728),stgcn_test[:,i],label='STCGCN (test)',color='C0')
a.plot(range(4,583),gnar_train[:,i],label='GNAR (train)',color='C1')
a.plot(range(583,728),gnar_test[:,i],label='GNAR (test)',color='C1')
a.legend()
fig.set_figwidth(14)
fig.suptitle("Scenario1: STGCN \n missing=0% \n interpolation=None \n\n STGCN: mse(train) = {0:.2f}, mse(test) = {1:.2f} \n GNAR: mse(train) = {2:.2f}, mse(test) = {3:.2f} \n".format(train_mse_total_stgcn,test_mse_total_stgcn,train_mse_total_gnar,test_mse_total_gnar),size=15)
fig.tight_layout()
fig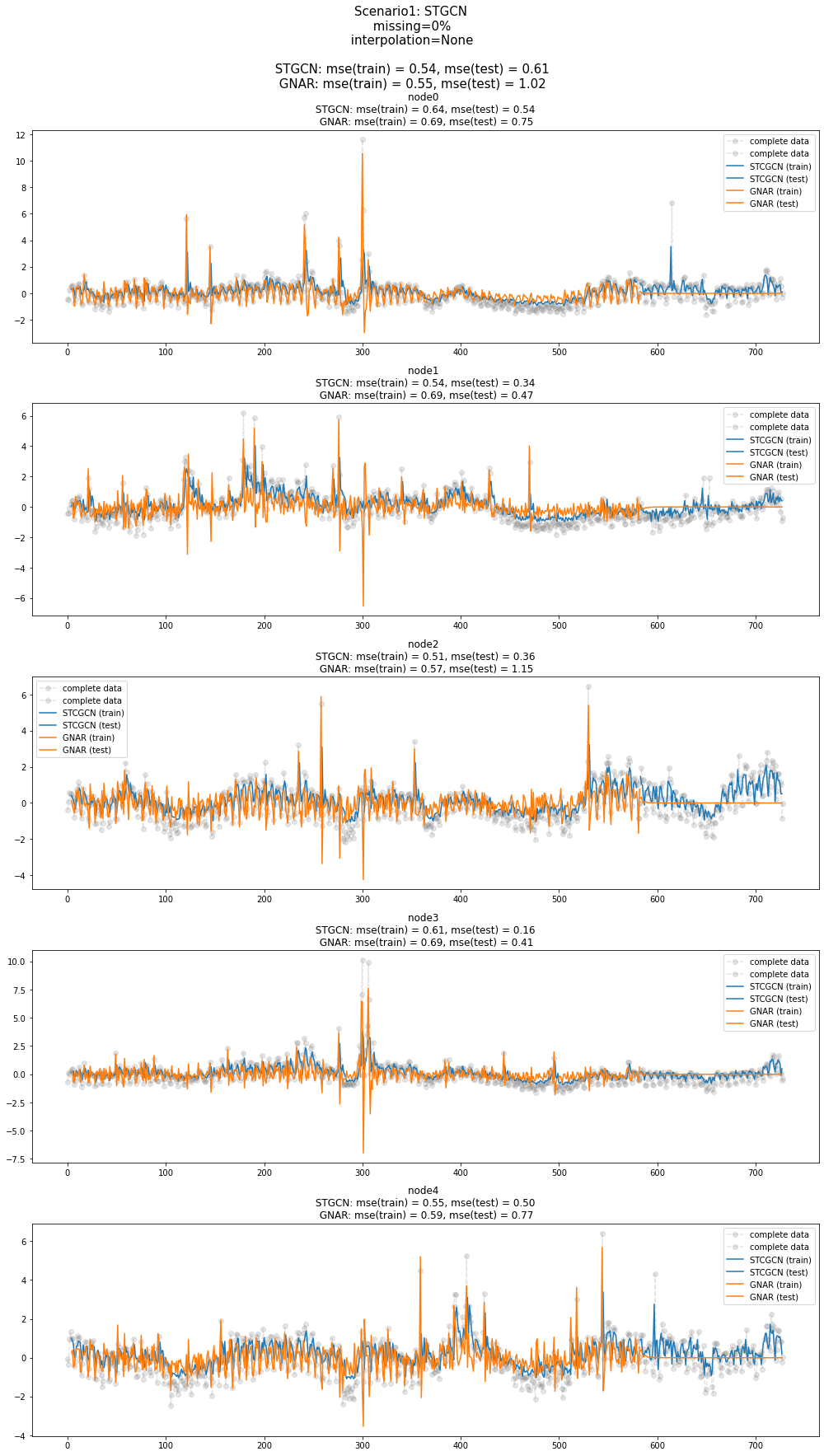
시나리오2
시나리오2
- missing rate: 50%
- 보간방법: linear
- 결측치생성 + 보간
_zero = Missing(x_train_f)
_zero.miss(percent = 0.5)
_zero.second_linear()missing_index = _zero.number
interpolated_signal = _zero.train_linearfig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.plot(missing_index[i],x_train[:,:,0][:,i][missing_index[i]],'xk',label='missing')
a.plot(interpolated_signal[:,i],'-',color='gray',label='linear interpolation')
a.legend()
fig.set_figwidth(15)
fig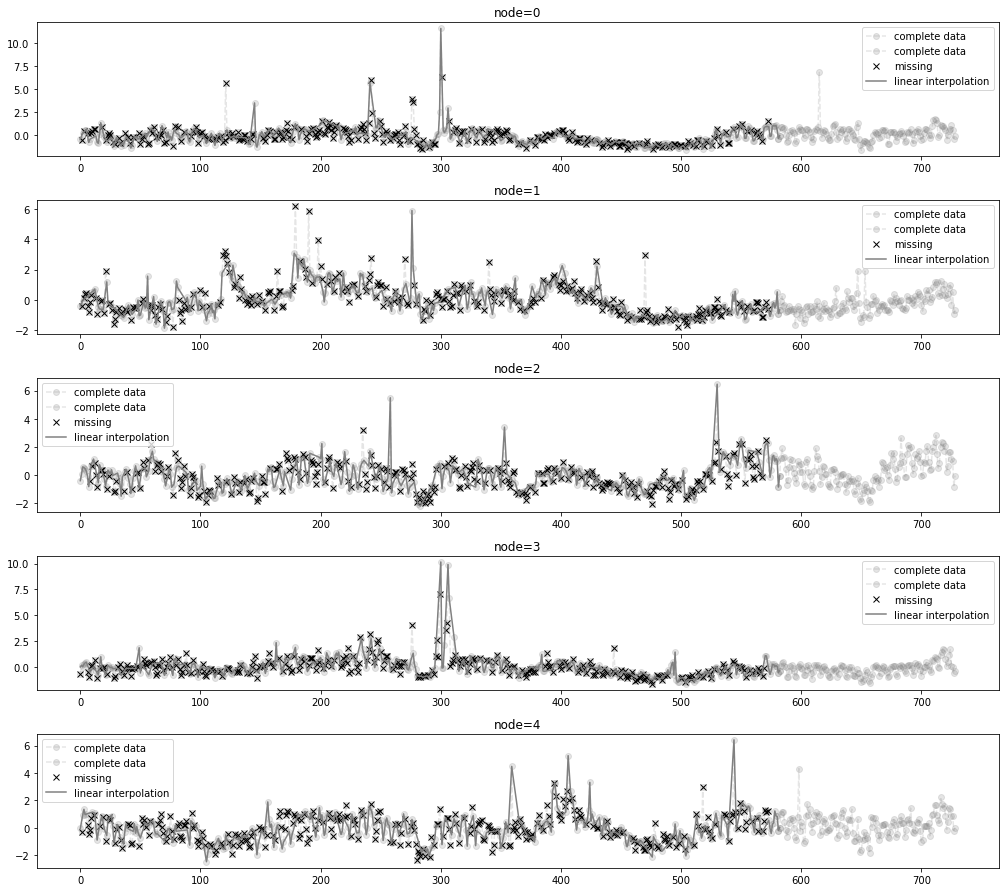
STGCN 으로 적합 + 예측
import numpy as np
T= 100
N= 5
lag =4
signal=np.arange(T*N).reshape(T,N)
X= np.stack([signal[i:(T-lag+i),:] for i in range(lag)],axis=-1)
X.shape
y=signal[lag:].reshape(T-lag,N,1)
y.shapeX = torch.tensor(np.stack([interpolated_signal[i:(T_train-4+i),:] for i in range(4)],axis = -1)).float()
y = torch.tensor(interpolated_signal[4:,:]).float()XX = x_test
yy = y_testnet = RecurrentGCN(node_features=4, filters=4)
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
net.train()
for epoch in tqdm(range(50)):
for time, (xt,yt) in enumerate(zip(X,y)):
yt_hat = net(xt, edge_index, edge_attr)
cost = torch.mean((yt_hat-yt)**2)
cost.backward()
optimizer.step()
optimizer.zero_grad()100%|██████████| 50/50 [06:23<00:00, 7.67s/it]yhat = torch.stack([net(xt, edge_index, edge_attr) for xt in X]).detach().numpy()
yyhat = torch.stack([net(xt, edge_index, edge_attr) for xt in XX]).detach().numpy()real_y = y_train[4:,:]
train_mse_eachnode_stgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean(axis=0)
train_mse_total_stgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean()
test_mse_eachnode_stgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean(axis=0)
test_mse_total_stgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean()stgcn_train = yhat.squeeze() # stgcn은 stgcn에 의한 적합결과를 의미함
stgcn_test = yyhat.squeeze() ESTGCN 으로 적합 + 예측
X = torch.tensor(np.stack([interpolated_signal[i:(T_train-4+i),:] for i in range(4)],axis = -1)).float()
y = torch.tensor(interpolated_signal[4:,:]).float()XX = x_test
yy = y_test- ESTGCN
net = RecurrentGCN(node_features=4, filters=4)
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
net.train()
signal = interpolated_signal.copy()
for epoch in tqdm(range(50)):
signal = update_from_freq_domain(signal,missing_index)
X = torch.tensor(np.stack([signal[i:(T_train+i),:] for i in range(4)],axis = -1)).reshape(T_train,N,4).float()
y = torch.tensor(signal).reshape(-1,N,1).float()[4:,:,:]
for time, (xt,yt) in enumerate(zip(X,y)):
yt_hat = net(xt, edge_index, edge_attr)
cost = torch.mean((yt_hat-yt)**2)
cost.backward()
optimizer.step()
optimizer.zero_grad()
signal = torch.concat([X[:-1,:,0], X[-1,:,:].T, yt_hat.detach().reshape(1,-1)]).squeeze()100%|██████████| 50/50 [07:11<00:00, 8.63s/it]- ESTGCN
yhat = torch.stack([net(xt, edge_index, edge_attr) for xt in X]).detach().numpy()
yyhat = torch.stack([net(xt, edge_index, edge_attr) for xt in XX]).detach().numpy()y_train.shape,T_train(torch.Size([580, 1068]), 580)real_y = y_train
train_mse_eachnode_estgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean(axis=0)
train_mse_total_estgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean()
test_mse_eachnode_estgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean(axis=0)
test_mse_total_estgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean()estgcn_train = yhat.squeeze() # stgcn은 stgcn에 의한 적합결과를 의미함
estgcn_test = yyhat.squeeze() GNAR 으로 적합 + 예측
-
X_gnar = np.array(torch.concat([X[:-1,:,0], x_train[-1,:,:].T]))
Edge = np.array(edge_index)w=np.zeros((1068,1068))for k in range(27079):
w[edge_index[0][k],edge_index[1][k]] = 1%R -i X_gnar
%R -i w
%R -i T_test%%R
wikiNet <- matrixtoGNAR(w)%%R
answer <- GNARfit(vts = X_gnar, net = wikiNet, alphaOrder = 4, betaOrder = c(1,1,1,1))
prediction <- predict(answer,n.ahead=T_test)%%R
gnar_train <- residuals(answer)
gnar_test <- prediction%R -o gnar_train
%R -o gnar_testtrain_mse_eachnode_gnar = (gnar_train**2).mean(axis=0)
train_mse_total_gnar = (gnar_train**2).mean()
test_mse_eachnode_gnar = ((y_test-gnar_test)**2).mean(axis=0)
test_mse_total_gnar = ((y_test-gnar_test)**2).mean()결과시각화
fig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,h=5)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.set_title('node{0} \n STGCN: mse(train) = {1:.2f}, mse(test) = {2:.2f} \n ESTGCN: mse(train) = {3:.2f}, mse(test) = {4:.2f}\n GNAR: mse(train) = {5:.2f}, mse(test) = {6:.2f}'.format(i,train_mse_eachnode_stgcn[i],test_mse_eachnode_stgcn[i],train_mse_eachnode_estgcn[i],test_mse_eachnode_estgcn[i],train_mse_eachnode_gnar[i],test_mse_eachnode_gnar[i]))
a.plot(missing_index[i],x_train[missing_index[i],i,0],'xk',label='missing')
a.plot(interpolated_signal[:,i],'-',color='gray',label='linear interpolation')
a.plot(range(4,580),stgcn_train.squeeze()[:,i],'--.',label='STCGCN (train)',color='C0')
a.plot(range(583,728),stgcn_test.squeeze()[:,i],'--.',label='STCGCN (test)',color='C0')
a.plot(range(4,584),estgcn_train.squeeze()[:,i],label='ESTCGCN (train)',color='C1')
a.plot(range(582,727),estgcn_test.squeeze()[:,i],label='ESTCGCN (test)',color='C1')
a.plot(range(4,583),gnar_train.squeeze()[:,i],label='GNAR (train)',color='C2')
a.plot(range(583,728),gnar_test.squeeze()[:,i],label='GNAR (test)',color='C2')
a.legend()
fig.set_figwidth(14)
fig.suptitle("Scenario2: \n missing=50% \n interpolation=linear \n\n STGCN: mse(train) = {0:.2f}, mse(test) = {1:.2f} \n ESTGCN: mse(train) = {2:.2f}, mse(test) = {3:.2f} \n GNAR: mse(train) = {4:.2f}, mse(test) = {5:.2f} \n".format(train_mse_total_stgcn,test_mse_total_stgcn,train_mse_total_estgcn,test_mse_total_estgcn,train_mse_total_gnar,test_mse_total_gnar),size=15)
fig.tight_layout()
fig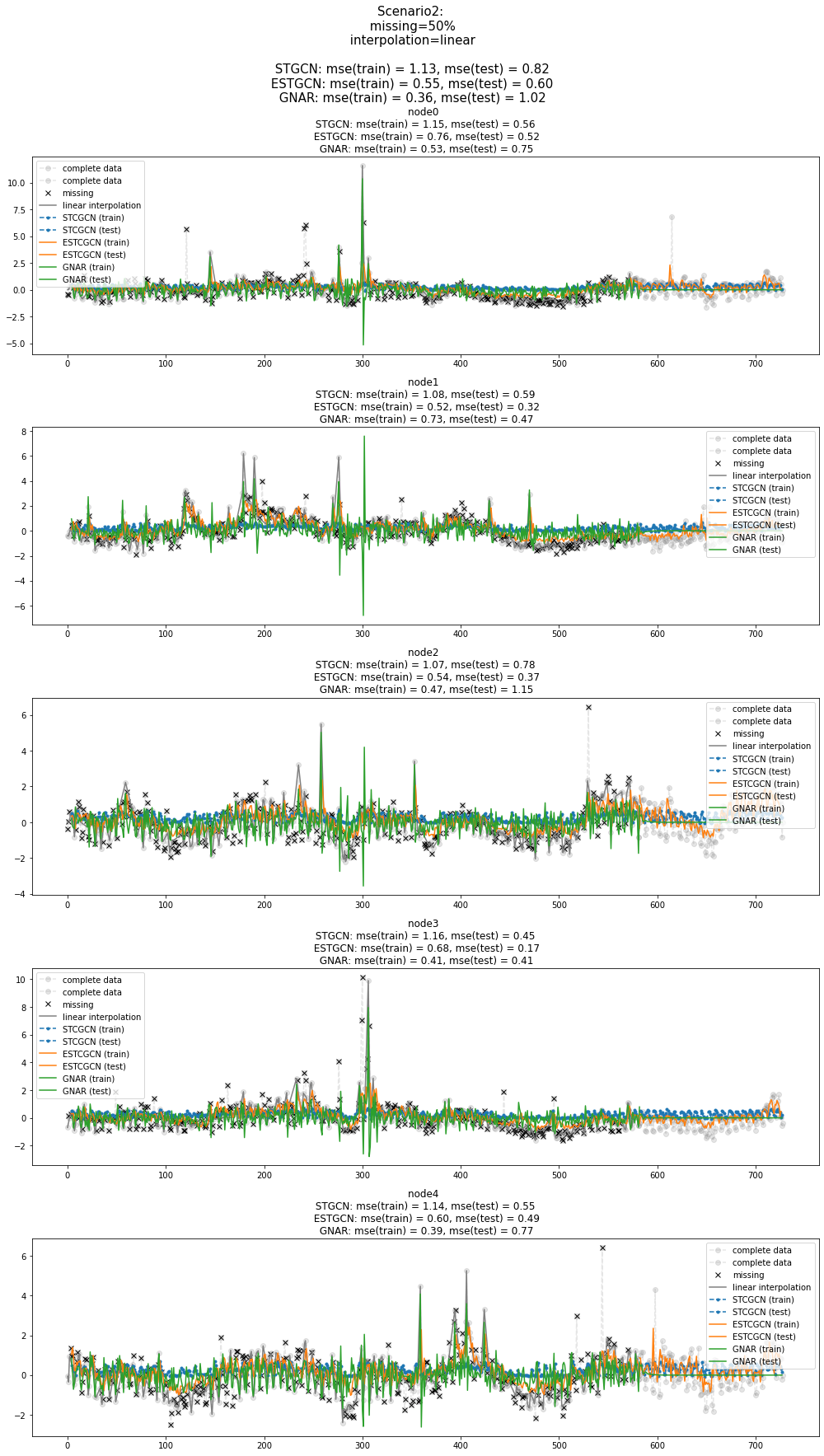
시나리오3
시나리오3
- missing rate: 80%
- 보간방법: linear
- 결측치생성 + 보간
_zero = Missing(x_train_f)
_zero.miss(percent = 0.8)
_zero.second_linear()missing_index = _zero.number
interpolated_signal = _zero.train_linearfig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,h=5)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.plot(missing_index[i],x_train_f[:,i][missing_index[i]],'xk',label='missing')
a.plot(interpolated_signal[:,i],'-',color='gray',label='linear interpolation')
a.legend()
fig.set_figwidth(15)
fig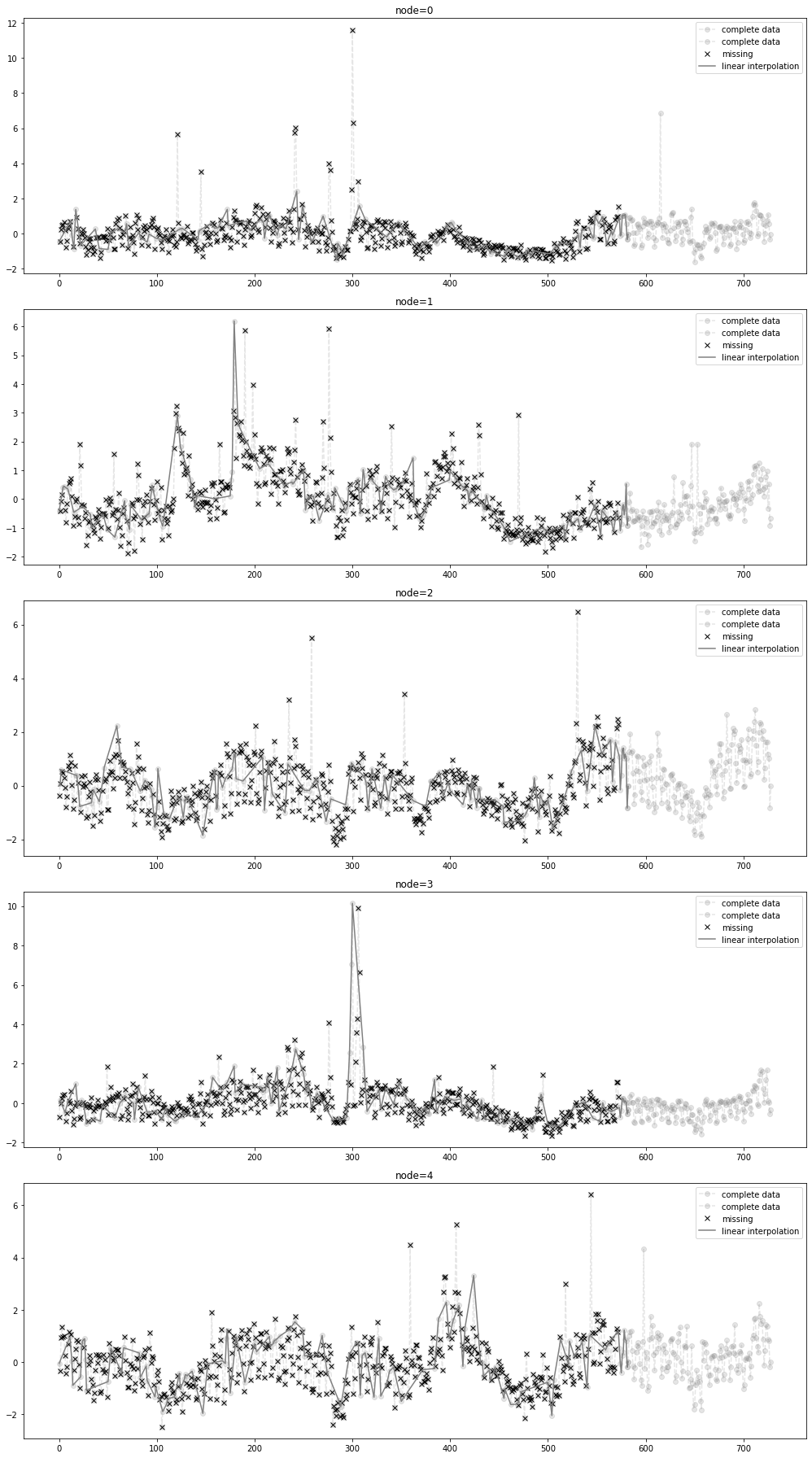
STGCN 으로 적합 + 예측
X = torch.tensor(np.stack([interpolated_signal[i:(T_train-4+i),:] for i in range(4)],axis = -1)).float()
y = torch.tensor(interpolated_signal[4:,:]).float()XX = x_test
yy = y_testnet = RecurrentGCN(node_features=4, filters=4)
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
net.train()
for epoch in tqdm(range(50)):
for time, (xt,yt) in enumerate(zip(X,y)):
yt_hat = net(xt, edge_index, edge_attr)
cost = torch.mean((yt_hat-yt)**2)
cost.backward()
optimizer.step()
optimizer.zero_grad()100%|██████████| 50/50 [06:40<00:00, 8.01s/it]yhat = torch.stack([net(xt, edge_index, edge_attr) for xt in X]).detach().numpy()
yyhat = torch.stack([net(xt, edge_index, edge_attr) for xt in XX]).detach().numpy()real_y = y_train[4:,:]
train_mse_eachnode_stgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean(axis=0)
train_mse_total_stgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean()
test_mse_eachnode_stgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean(axis=0)
test_mse_total_stgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean()stgcn_train = yhat.squeeze() # stgcn은 stgcn에 의한 적합결과를 의미함
stgcn_test = yyhat.squeeze() ESTGCN 으로 적합 + 예측
X = torch.tensor(np.stack([interpolated_signal[i:(T_train-4+i),:] for i in range(4)],axis = -1)).float()
y = torch.tensor(interpolated_signal[4:,:]).float()XX = x_test
yy = y_test- ESTGCN
net = RecurrentGCN(node_features=4, filters=4)
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
net.train()
signal = interpolated_signal.copy()
for epoch in tqdm(range(50)):
signal = update_from_freq_domain(signal,missing_index)
X = torch.tensor(np.stack([signal[i:(T_train+i),:] for i in range(4)],axis = -1)).reshape(T_train,N,4).float()
y = torch.tensor(signal).reshape(-1,N,1).float()[4:,:,:]
for time, (xt,yt) in enumerate(zip(X,y)):
yt_hat = net(xt, edge_index, edge_attr)
cost = torch.mean((yt_hat-yt)**2)
cost.backward()
optimizer.step()
optimizer.zero_grad()
signal = torch.concat([X[:-1,:,0], X[-1,:,:].T, yt_hat.detach().reshape(1,-1)]).squeeze()100%|██████████| 50/50 [07:18<00:00, 8.77s/it]yhat = torch.stack([net(xt, edge_index, edge_attr) for xt in X]).detach().numpy()
yyhat = torch.stack([net(xt, edge_index, edge_attr) for xt in XX]).detach().numpy()real_y = y_train
train_mse_eachnode_estgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean(axis=0)
train_mse_total_estgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean()
test_mse_eachnode_estgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean(axis=0)
test_mse_total_estgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean()estgcn_train = yhat.squeeze() # stgcn은 stgcn에 의한 적합결과를 의미함
estgcn_test = yyhat.squeeze() GNAR 으로 적합 + 예측
-
X_gnar = np.array(torch.concat([X[:-1,:,0], x_train[-1,:,:].T]))
Edge = np.array(edge_index)w=np.zeros((1068,1068))for k in range(27079):
w[edge_index[0][k],edge_index[1][k]] = 1%R -i X_gnar
%R -i w
%R -i T_test%%R
wikiNet <- matrixtoGNAR(w)%%R
answer <- GNARfit(vts = X_gnar, net = wikiNet, alphaOrder = 4, betaOrder = c(1,1,1,1))
prediction <- predict(answer,n.ahead=T_test)%%R
gnar_train <- residuals(answer)
gnar_test <- prediction%R -o gnar_train
%R -o gnar_testtrain_mse_eachnode_gnar = (gnar_train**2).mean(axis=0)
train_mse_total_gnar = (gnar_train**2).mean()
test_mse_eachnode_gnar = ((y_test-gnar_test)**2).mean(axis=0)
test_mse_total_gnar = ((y_test-gnar_test)**2).mean()결과시각화
fig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,h=5)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.set_title('node{0} \n STGCN: mse(train) = {1:.2f}, mse(test) = {2:.2f} \n ESTGCN: mse(train) = {3:.2f}, mse(test) = {4:.2f}\n GNAR: mse(train) = {5:.2f}, mse(test) = {6:.2f}'.format(i,train_mse_eachnode_stgcn[i],test_mse_eachnode_stgcn[i],train_mse_eachnode_estgcn[i],test_mse_eachnode_estgcn[i],train_mse_eachnode_gnar[i],test_mse_eachnode_gnar[i]))
a.plot(missing_index[i],x_train[missing_index[i],i,0],'xk',label='missing')
a.plot(interpolated_signal[:,i],'-',color='gray',label='linear interpolation')
a.plot(range(4,580),stgcn_train.squeeze()[:,i],'--.',label='STCGCN (train)',color='C0')
a.plot(range(583,728),stgcn_test.squeeze()[:,i],'--.',label='STCGCN (test)',color='C0')
a.plot(range(4,584),estgcn_train.squeeze()[:,i],label='ESTCGCN (train)',color='C1')
a.plot(range(582,727),estgcn_test.squeeze()[:,i],label='ESTCGCN (test)',color='C1')
a.plot(range(4,583),gnar_train.squeeze()[:,i],label='GNAR (train)',color='C2')
a.plot(range(583,728),gnar_test.squeeze()[:,i],label='GNAR (test)',color='C2')
a.legend()
fig.set_figwidth(14)
fig.suptitle("Scenario2: \n missing=50% \n interpolation=linear \n\n STGCN: mse(train) = {0:.2f}, mse(test) = {1:.2f} \n ESTGCN: mse(train) = {2:.2f}, mse(test) = {3:.2f} \n GNAR: mse(train) = {4:.2f}, mse(test) = {5:.2f} \n".format(train_mse_total_stgcn,test_mse_total_stgcn,train_mse_total_estgcn,test_mse_total_estgcn,train_mse_total_gnar,test_mse_total_gnar),size=15)
fig.tight_layout()
fig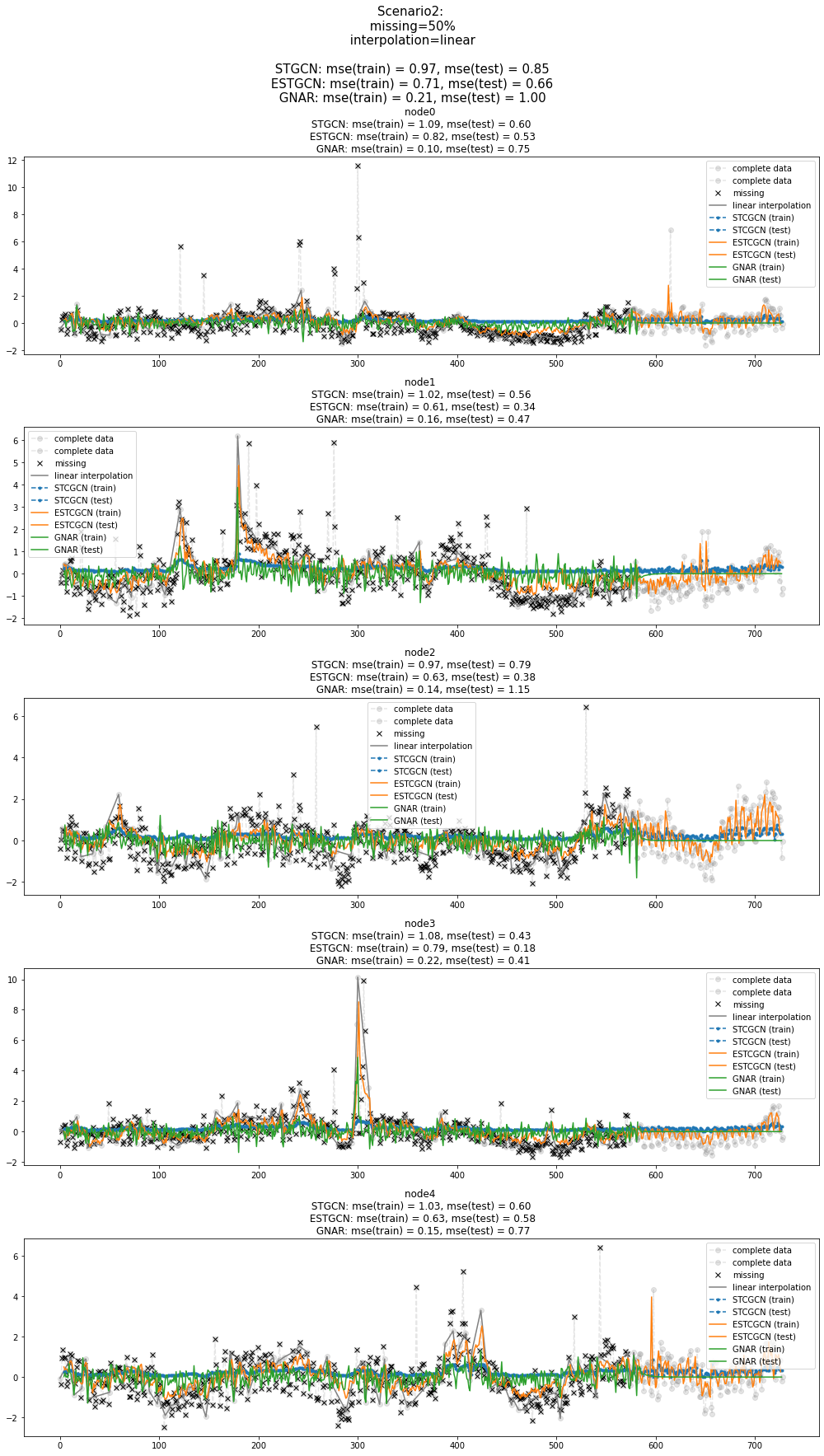
시나리오4
시나리오4
- missing rate: 30%
- 보간방법: linear
- 결측치생성 + 보간
_zero = Missing(x_train_f)
_zero.miss(percent = 0.3)
_zero.second_linear()missing_index = _zero.number
interpolated_signal = _zero.train_linearfig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,h=5)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.plot(missing_index[i],x_train_f[:,i][missing_index[i]],'xk',label='missing')
a.plot(interpolated_signal[:,i],'-',color='gray',label='linear interpolation')
a.legend()
fig.set_figwidth(15)
fig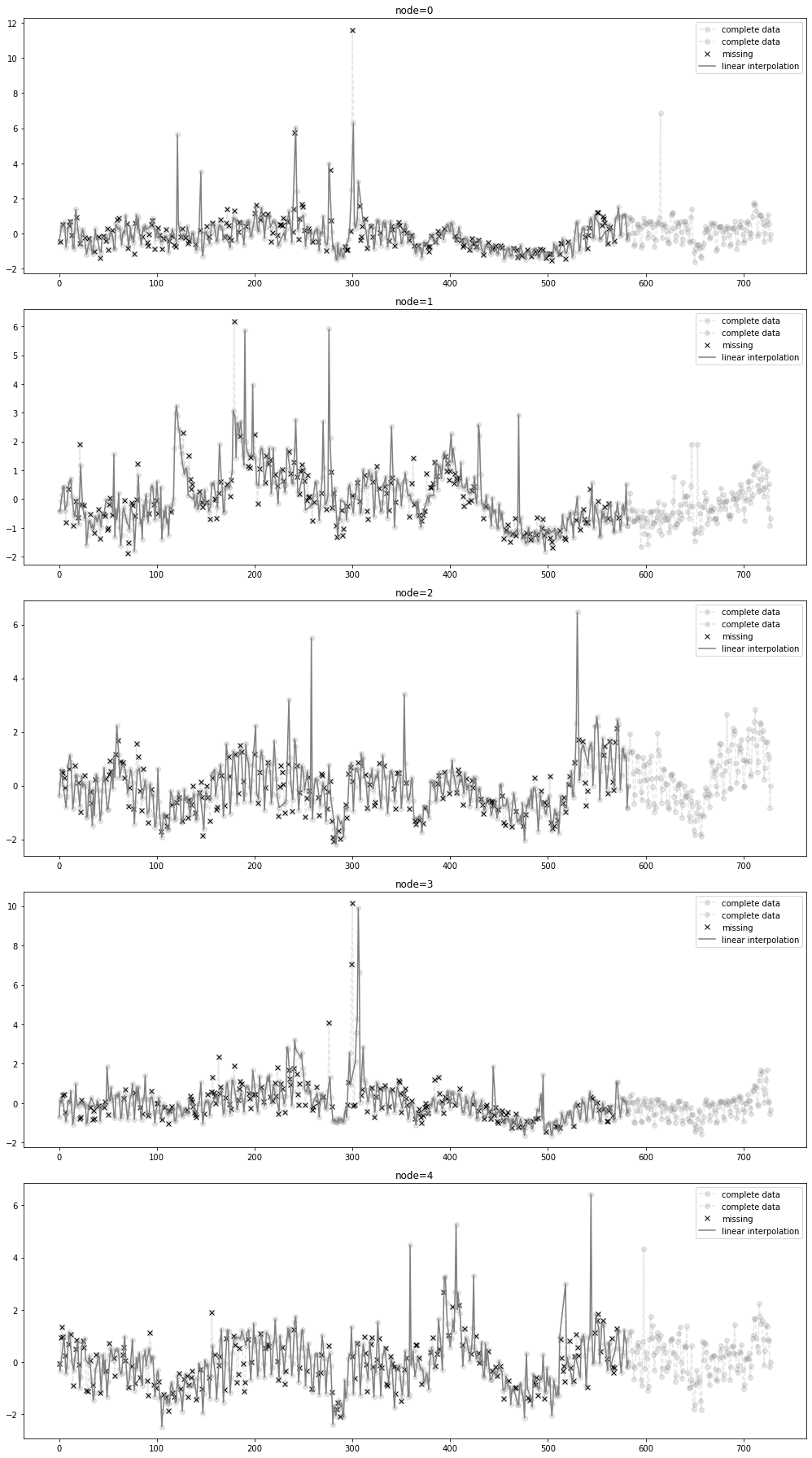
STGCN 으로 적합 + 예측
X = torch.tensor(np.stack([interpolated_signal[i:(T_train-4+i),:] for i in range(4)],axis = -1)).float()
y = torch.tensor(interpolated_signal[4:,:]).float()XX = x_test
yy = y_testnet = RecurrentGCN(node_features=4, filters=4)
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
net.train()
for epoch in tqdm(range(50)):
for time, (xt,yt) in enumerate(zip(X,y)):
yt_hat = net(xt, edge_index, edge_attr)
cost = torch.mean((yt_hat-yt)**2)
cost.backward()
optimizer.step()
optimizer.zero_grad()100%|██████████| 50/50 [06:32<00:00, 7.86s/it]yhat = torch.stack([net(xt, edge_index, edge_attr) for xt in X]).detach().numpy()
yyhat = torch.stack([net(xt, edge_index, edge_attr) for xt in XX]).detach().numpy()real_y = y_train[4:,:]
train_mse_eachnode_stgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean(axis=0)
train_mse_total_stgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean()
test_mse_eachnode_stgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean(axis=0)
test_mse_total_stgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean()stgcn_train = yhat.squeeze() # stgcn은 stgcn에 의한 적합결과를 의미함
stgcn_test = yyhat.squeeze() ESTGCN 으로 적합 + 예측
X = torch.tensor(np.stack([interpolated_signal[i:(T_train-4+i),:] for i in range(4)],axis = -1)).float()
y = torch.tensor(interpolated_signal[4:,:]).float()XX = x_test
yy = y_test- ESTGCN
net = RecurrentGCN(node_features=4, filters=4)
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
net.train()
signal = interpolated_signal.copy()
for epoch in tqdm(range(50)):
signal = update_from_freq_domain(signal,missing_index)
X = torch.tensor(np.stack([signal[i:(T_train+i),:] for i in range(4)],axis = -1)).reshape(T_train,N,4).float()
y = torch.tensor(signal).reshape(-1,N,1).float()[4:,:,:]
for time, (xt,yt) in enumerate(zip(X,y)):
yt_hat = net(xt, edge_index, edge_attr)
cost = torch.mean((yt_hat-yt)**2)
cost.backward()
optimizer.step()
optimizer.zero_grad()
signal = torch.concat([X[:-1,:,0], X[-1,:,:].T, yt_hat.detach().reshape(1,-1)]).squeeze()100%|██████████| 50/50 [07:13<00:00, 8.66s/it]yhat = torch.stack([net(xt, edge_index, edge_attr) for xt in X]).detach().numpy()
yyhat = torch.stack([net(xt, edge_index, edge_attr) for xt in XX]).detach().numpy()real_y = y_train
train_mse_eachnode_estgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean(axis=0)
train_mse_total_estgcn = (((real_y-yhat.squeeze()).squeeze())**2).mean()
test_mse_eachnode_estgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean(axis=0)
test_mse_total_estgcn = (((yy-yyhat.squeeze()).squeeze())**2).mean()estgcn_train = yhat.squeeze() # stgcn은 stgcn에 의한 적합결과를 의미함
estgcn_test = yyhat.squeeze() GNAR 으로 적합 + 예측
-
X_gnar = np.array(torch.concat([X[:-1,:,0], x_train[-1,:,:].T]))
Edge = np.array(edge_index)w=np.zeros((1068,1068))for k in range(27079):
w[edge_index[0][k],edge_index[1][k]] = 1%R -i X_gnar
%R -i w
%R -i T_test%%R
wikiNet <- matrixtoGNAR(w)%%R
answer <- GNARfit(vts = X_gnar, net = wikiNet, alphaOrder = 4, betaOrder = c(1,1,1,1))
prediction <- predict(answer,n.ahead=T_test)%%R
gnar_train <- residuals(answer)
gnar_test <- prediction%R -o gnar_train
%R -o gnar_testtrain_mse_eachnode_gnar = (gnar_train**2).mean(axis=0)
train_mse_total_gnar = (gnar_train**2).mean()
test_mse_eachnode_gnar = ((y_test-gnar_test)**2).mean(axis=0)
test_mse_total_gnar = ((y_test-gnar_test)**2).mean()결과시각화
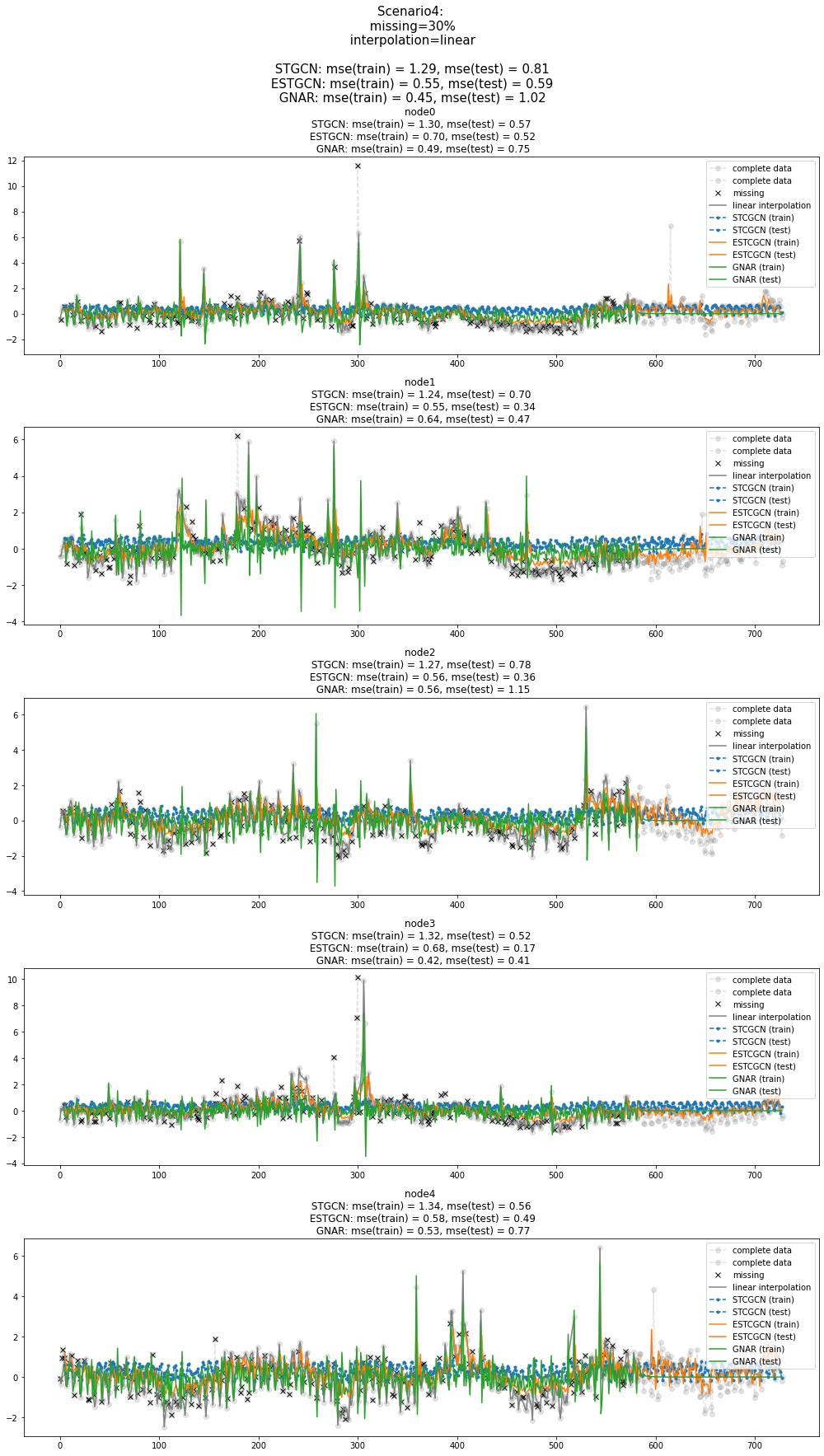
fig = plot(x_train_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,h=5)
fig = plot_add(fig,x_test_f[:,:5],'--o',color='gray',label='complete data',alpha=0.2,t=range(581,729))
ax = fig.get_axes()
for i,a in enumerate(ax):
a.set_title('node{0} \n STGCN: mse(train) = {1:.2f}, mse(test) = {2:.2f} \n ESTGCN: mse(train) = {3:.2f}, mse(test) = {4:.2f}\n GNAR: mse(train) = {5:.2f}, mse(test) = {6:.2f}'.format(i,train_mse_eachnode_stgcn[i],test_mse_eachnode_stgcn[i],train_mse_eachnode_estgcn[i],test_mse_eachnode_estgcn[i],train_mse_eachnode_gnar[i],test_mse_eachnode_gnar[i]))
a.plot(missing_index[i],x_train[missing_index[i],i,0],'xk',label='missing')
a.plot(interpolated_signal[:,i],'-',color='gray',label='linear interpolation')
a.plot(range(4,580),stgcn_train.squeeze()[:,i],'--.',label='STCGCN (train)',color='C0')
a.plot(range(583,728),stgcn_test.squeeze()[:,i],'--.',label='STCGCN (test)',color='C0')
a.plot(range(4,584),estgcn_train.squeeze()[:,i],label='ESTCGCN (train)',color='C1')
a.plot(range(582,727),estgcn_test.squeeze()[:,i],label='ESTCGCN (test)',color='C1')
a.plot(range(4,583),gnar_train.squeeze()[:,i],label='GNAR (train)',color='C2')
a.plot(range(583,728),gnar_test.squeeze()[:,i],label='GNAR (test)',color='C2')
a.legend()
fig.set_figwidth(14)
fig.suptitle("Scenario4: \n missing=30% \n interpolation=linear \n\n STGCN: mse(train) = {0:.2f}, mse(test) = {1:.2f} \n ESTGCN: mse(train) = {2:.2f}, mse(test) = {3:.2f} \n GNAR: mse(train) = {4:.2f}, mse(test) = {5:.2f} \n".format(train_mse_total_stgcn,test_mse_total_stgcn,train_mse_total_estgcn,test_mse_total_estgcn,train_mse_total_gnar,test_mse_total_gnar),size=15)
fig.tight_layout()
fig